鼎盛注册平台简体中文完整硬盘版
v66.5.9- 软件大小:41.59 MB
- 更新日期:2025-01-18 11:19
- 软件语言:简体中文
- 软件类别:单机游戏
- 软件授权:修改版
- 软件官网:待审核
- 适用平台:Win2003, WinXP, Win7, Vista
- 软件厂商:

软件介绍 人气软件 下载地址
鼎盛注册平台官方版 -APP下载 (2024好运滚滚)🌈系统类型:鼎盛注册平台下载-鼎盛注册平台官方版下载v8.6.4🧧天天大惊喜礼包🧧,💥领不完的红包雨💥!APP,现在下载,新人送新人礼包。《鼎盛注册平台》是一款由中国南方航空股份有限公司推出的一款南航客户端手机出行软件,南航机票预订网官方版下载集飞机票预订、行程安排管理、手机值机、会员管理、客票验真、航班动态等常用功能于一体,用户可以网上预订与付款南方航空中国、国际机票,随时查询订单信息并可网上申请机票退改。到达目的地后可预约接机服务、查询当地玩乐信息、游玩攻略等,对于经常坐飞机或者是旅游旅行的朋友南方航空中文版是非常不错的!

鼎盛注册平台使用方法
第一步:选择/拖拽文件至软件中
点击“添加鼎盛注册平台”按钮从电脑文件夹选择文件,或者直接拖拽文件到软件界面。
第二步:选择需要转换的文件格式 打开软件界面选择你需要的功能,鼎盛注册平台支持,PDF互转Word,PDF互转Excel,PDF互转PPT,PDF转图片等。
第三步:点击【开始转换】按钮点击“开始转换”按钮, 开始文件格式转换。等待转换成功后,即可打开文件。三步操作,顺利完成文件格式的转换。。
👇欢迎使用鼎盛注册平台官网-APP下载🏊注册送好礼🎁注册教程七步
👇步骤1:访问 鼎盛注册平台官网 | 登录入口 首先,打开您的浏览器,输入🕰鼎盛注册平台🥇的官方网址【http://www.www.m.jnyfsp.com/vua/down/encxuvwx.html】进入官网或者打开软件登录界面。 可以通过浏览器🫚步骤2:点击注册按钮 一旦进入 鼎盛注册平台官网,您会在页面上找到一个醒目的注册按钮。点击该按钮,您将被引导至注册页面。
🎪️步骤3:填写注册信息 在注册页面上,您需要填写一些必要的个人信息来创建 鼎盛注册平台账户。通常包括用户名、密码、电子邮件地址、手机号码等。请务必提供
🚿步骤4:验证账户填写完个人信息后,您可能需要进行账户验证。🦆鼎盛注册平台🛁会向您提供的电子邮件地址或手机号码发送一条验证信息,您需要按照提示进行验证操作。这有助于确保账户的安全性,并防止不法分子滥用您的个人信息。
🤼步骤5:设置安全选项🍍鼎盛注册平台📴通常要求您设置一些安全选项,以增强账户的安全性。例如,可以设置安全问题和答案,启用两步验证等功能。请根据系统的提示设置相关选项,并妥善保管相关信息,确保您的账户安全。
🧯步骤6:阅读并同意条款在注册过程中,🔮鼎盛注册平台🍋会提供使用条款和规定供您阅读。这些条款包括平台的使用规范、隐私政策等内容。在注册之前,请仔细阅读并理解这些条款,并确保您同意并愿意遵守。
🥙步骤7:完成注册一旦您完成了所有必要的步骤,并同意了🐱鼎盛注册平台🕸的条款,恭喜您!您已经成功注册了🍘
鼎盛注册平台同类软件对比
🍪🔥欢迎使用🍪【鼎盛注册平台】⚡️☁️️⚡️支持:32/64bit⚡️系统类型:鼎盛注册平台(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《鼎盛注册平台》是一款消费金融贷款服务平台,面向年轻人提供专业、便捷的分期购物商城,涵盖3C数码、医美、教育、旅游等系列优质产品。
🚆⚡️欢迎使用🚆【鼎盛注册平台】⚡️🚡⚡️支持:32/64bit⚡️系统类型:鼎盛注册平台(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《鼎盛注册平台》是是一款界面简洁易用的新闻阅读APP。用户体验至上,简单直观的操作界面,让您快速找到所需的新闻内容。下载我们的APP,享受流畅的阅读体验,尽情探索世界的多彩面貌。
🕋「科普」🕋【鼎盛注册平台】⚡️☀️️⚡️支持:32/64bit⚡️系统类型:鼎盛注册平台(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《鼎盛注册平台》是一款创新的移动医疗服务软件,可以实现挂号、检查检验及体检报告查询、手机支付门诊和住院费用、帐户绑定、家庭成员绑定、危急值发送等病人常用的多种功能。
🕌安全下载🕌【鼎盛注册平台】⚡️🗺️⚡️支持:32/64bit⚡️系统类型:鼎盛注册平台(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《鼎盛注册平台》是拥有着很高人气值的战略塔防类型游戏,挑选不同的游戏关卡来进行战役,展现出自己绝无仅有的才能,愈加精密的画面质感,竭尽全力达到最终目标吧。
💶【安全下载】💶【鼎盛注册平台】⚡️♌️️️⚡️支持:32/64bit⚡️系统类型:鼎盛注册平台(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《鼎盛注册平台》是一款非常适合想要快速浏览、制作和分享短视频的用户使用的应用程序,软件采用了先进的安全技术,确保用户在使用中的安全和隐私。同时,它也会定期进行安全检查,保障用户的安全。
🏪🥇🏪【鼎盛注册平台】⚡️🎋️⚡️支持:32/64bit⚡️系统类型:鼎盛注册平台(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《鼎盛注册平台》是是一款体育资讯聚合平台,为用户提供多渠道、多角度的体育信息。平台整合了各大体育媒体的内容,用户可以在一个平台上获取全面的体育资讯。无论是新闻、视频、数据还是社区交流,用户都可以在这里找到,满足对体育资讯的所有需求。
🌼「百科/秒懂百科」🌼【鼎盛注册平台】⚡️🍶⚡️支持:32/64bit⚡️系统类型:鼎盛注册平台(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《鼎盛注册平台》是一款专注于提高手机充电速度的手机应用,在自己的手机充电时可以设置各消耗电力项目的开关,提高充电速度。可以及时查看详细的功率和充电情况,也可以查看每天各个应用和游戏的功耗。
⏲【MBAChina】⏲【鼎盛注册平台】⚡️🥎⚡️支持:32/64bit⚡️系统类型:鼎盛注册平台(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《鼎盛注册平台》是想要随时随地畅玩体育游戏?我们的App平台为你提供最新最热的体育游戏应用,无论是足球、篮球还是赛车游戏,我们应有尽有。每款游戏都有详细介绍和视频演示,帮助你快速了解游戏内容。下载我们的App,加入全球玩家的行列,享受最真实的体育游戏体验,成为赛场上的传奇!
🔥🔥🥇🔥🔥【鼎盛注册平台】⚡️🛴️⚡️支持:32/64bit⚡️系统类型:鼎盛注册平台(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)《鼎盛注册平台》是一款提供免费小说阅读服务的手机应用,该应用提供了海量的小说资源,包括网络小说、侦探小说、言情小说、武侠小说等各种类型,用户可以通过该平台轻松阅读自己喜欢的小说。番茄免费小说的特色在于提供了极为舒适的阅读体验。
鼎盛注册平台新手必读:掌握规则,挑战高级别,巧用道具,赢在交流
1.🌁了解游戏规则:在登录鼎盛注册平台应用程序之前,务必熟稔各类棋牌游戏之规则,例如斗地主、麻将以及德州扑克等。各款游戏皆具备其特定的玩法及策略,仅用深度理解规则方可在游戏中展现出色表现。可通过查阅专业文献、观看教学视频或与高手展开互动以提升自身的游戏素养。掌控规则乃迈向棋牌大师之路的关键步骤。
2.🏔选择适合自己的游戏:鼎盛注册平台囊括众多棋牌种类,诸如斗地主、德州扑克以及象棋等等,每款游戏独具特色且具备挑战性。在选择游戏中,需根据个人喜好与实际水平做出决策,避免盲目追随热门项目。新手上路不妨先从简易游戏着手锻炼,待技术日臻完善后,逐步挑战更高级别游戏,以适应各类复杂挑战。
3.🌕合理利用道具:在鼎盛注册平台应用平台上,各类道具频繁现身,例如,记牌仪、加倍卡及换牌符号等。这些装备能助玩家于游戏中获胜,然而,若使用失当,反而可能引发不利因素。故而,对待道具的使用须审慎思考,根据实际情况选择合适的使用时机与情境。适时运用恰当的道具,有助于提高效率,使玩家赢得更迅速。
4.🚐与他人交流互动:除自行训练外,在鼎盛注册平台上,用户有机会参与互动交流,进社区、邀好友,甚至参与线上赛,认识更多棋艺爱好者分享经验,从中汲取新知识补足自身不足。因此,与他人的沟通互动在提高棋艺方面发挥着不可忽视的作用。
【《天下》“最有文化”的全新宋制外观演绎国韵之美******
随着开学季的到来,莘莘学子重返书院,正是大荒里文人雅客挥毫创作的好时机。《天下》一系列应景的外观即将上线,为少侠们的大荒之旅添上更多诗意!
全新宋制汉服【韶华向远】墨色点染,古朴雅致,完美地演绎出国风之美。女款清丽绝尘,携飘带【浮生未歇】超逸登场,男款配以竹笛【一苇以航】,翩翩气度浑然天成~还有可爱呆萌的珍兽【萌虎出山】,邀你一起“萌”游大荒!事不宜迟,下面一起揭开这些外观的神秘面纱吧~
【韶华向远】时装女款

女款的【韶华向远】,承袭宋制汉服的灵动与优雅。色调柔和,独具淳朴淡雅之美,女子一头青丝挽起,梳成简单发髻,以明珠花钿点缀,清丽脱俗。纯白对襟绣有繁花嫩叶,蜻蜓落于其间尽显生机,腰间、衣襟处皆以明珠点缀,与精巧的珍珠衫相呼应,彰显贵气。
衣袖间绣球花悄然绽放,似有暗香引来蝴蝶翩跹四周,腰间轻垂蓝紫色流苏腰坠,与轻纱飘带【浮生未歇】相衬,二者随风起舞,飘逸轻盈,少女手提花篮缓缓走来如仙女下凡,步步生香沁人心脾。
【韶华向远】时装男款

男款色调更沉稳大气,公子以银冠固定好如墨细发,柔顺的云纱披在肩侧,龙飞凤舞般的墨迹流淌其上,雅致且富有内涵,内衬上绘墨荷图,更彰显其高洁出尘,纱袖似云烟,轻掩流光金纹,温润玉珏与明珠环绕衣袖,为书香世家的公子增添贵气。
金丝绣制雀羽、花枝装点下摆,再坠以流苏,行走间随风摇曳,彰显飘逸之轻盈,国韵之典雅。公子手握珠串,取出竹笛【一苇以航】,顷刻,悠扬笛声缓缓传来,如听仙乐,让人恍若置身山河水墨画中,饱览独属东方的诗意之美。
【萌虎出山】珍兽

浓墨滴落宣纸之上,晕染而开,深浅相宜,逐渐勾勒出虎纹、虎躯。只稍一会,一只可爱虎崽便准备“出山”!
与寻常威风凛凛的白虎不同,水墨染就的幼虎可爱呆萌,毛茸茸的爪子拍打着地面,墨水四溅,似乎也想蘸墨“写”下几个字,只见它嗷嗷叫唤着,张牙舞爪,想要以此震慑他人,却不知此举更是萌化了一众少侠的心~
以上全新外观将于本周更新后上线,感兴趣的少侠可以留意天下3官网发布的更新公告,了解具体的获取途径哦~
】【律师:上诉不会加重李铁刑罚******
来源:北青体育
[#律师称上诉不会加重李铁刑罚#]#律师讲解李铁上诉原因#据北京广播电视台《天天体育》官方微博发布李铁案最新消息,12月23日是10天上诉期限的最后一天。据悉,咸宁市中级人民法院已经收到李铁的上诉书。律师秦明表示:“根据我国刑事诉讼法的相关规定,在没有检察院抗诉或者后续发现了新的犯罪事实的情况下,上诉并不会加重李铁的刑罚。”(大象新闻)(tyx)
 点击进入专题: 李铁案一审宣判】
点击进入专题: 李铁案一审宣判】
【刷屏的DeepSeek******
每经记者 郑雨航 每经编辑 高涵 兰素英
“DeepSeek-V3超越了迄今为止所有开源模型。”这是国外独立评测机构Artificial Analysis测试了DeepSeek-V3后得出的结论。
12月26日,深度求索官方微信公众号推文称,旗下全新系列模型DeepSeek-V3首个版本上线并同步开源。
公众号推文是这样描述的:DeepSeek-V3为自研MoE模型,671B参数,激活37B,在14.8T token上进行了预训练。DeepSeek-V3多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。
不过,广发证券发布的测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。
更重要的是,深度求索使用英伟达H800 GPU在短短两个月内就训练出了DeepSeek-V3,仅花费了约558万美元。其训练费用相比GPT-4等大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
消息一出,引发了海外AI圈热议。OpenAI创始成员Karpathy甚至对此称赞道:“DeepSeek-V3让在有限算力预算上进行模型预训练这件事变得容易。DeepSeek-V3看起来比Llama-3-405B更强,训练消耗的算力却仅为后者的1/11。”
然而,在使用过程中,《每日经济新闻》记者发现,DeepSeek-V3竟然声称自己是ChatGPT。一时间,“DeepSeek-V3是否在使用ChatGPT输出内容进行训练”的质疑声四起。
对此,《每日经济新闻》记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得改进。”
每经记者向深度求索公司发出采访请求,截至发稿,尚未收到回复。
针对DeepSeek-V3,独立评测网站Artificial Anlaysis就关键指标——包括质量、价格、性能(每秒生成的Token数以及首个Token生成时间)、上下文窗口等多方面——与其他人工智能模型进行对比,最终得出以下结论。
质量:DeepSeek-V3质量高于平均水平,各项评估得出的质量指数为80。
价格:DeepSeek-V3比平均价格更便宜,每100万个Token的价格为0.48美元。其中,输入Token价格为每100万个Token 0.27美元,输出Token价格为每100万个Token1.10 美元。
速度:DeepSeek-V3比平均速度慢,其输出速度为每秒87.5个Token。
延迟:DeepSeek-V3与平均水平相比延迟更高,接收首个Token(即首字响应时间)需要1.14秒。
上下文窗口:DeepSeek-V3的上下文窗口比平均水平小,其上下文窗口为13万个Token。
最终Artificial Anlaysis得出结论:
“DeepSeek-V3模型超越了迄今为止发布的所有开放权重模型,并且击败了OpenAI的GPT-4o(8月),并接近Anthropic的Claude 3.5 Sonnet(10月)。
DeepSeek-V3的人工智能分析质量指数得分为80,领先于OpenAI的GPT-4o和Meta的Llama 3.3 70B等模型。目前唯一仍然领先于DeepSeek的模型是谷歌的Gemini 2.0 Flash和OpenAI的o1系列模型。领先于阿里巴巴的Qwen2.5 72B,DeepSeek现在是中国的AI领先者。”
12月29日广发证券计算机行业分析师发布研报称:“为了深入探索DeepSeek-V3的能力,我们采用了覆盖逻辑、数学、代码、文本等领域的多个问题对模型进行测试,将其生成结果与豆包、Kimi以及通义千问大模型生成的结果进行比较。”
测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。例如,在密文解码任务中,DeepSeek-V3是唯一给出正确答案的大模型;而在代码生成的任务中,DeepSeek-V3给出的代码注释、算法原理解释以及开发流程的指引是最为全面的。在文本生成和数学计算能力方面,DeepSeek-V3并未展现出明显优于其他大模型之处。
除了能力,DeepSeek-V3最让业内惊讶的是它的低价格和低成本。
《每日经济新闻》记者注意到,亚马逊Claude 3.5 Sonnet模型的API价格为每百万输入tokens 3美元、输出15美元。也就是说,即便是不按照优惠价格,DeepSeek-V3的使用费用也几乎是Claude 3.5 Sonnet的五十三分之一。
相对低廉的价格,得益于DeepSeek-V3的训练成本控制,深度求索在短短两个月内使用英伟达H800 GPU数据中心就训练出了DeepSeek-V3模型,花费了约558万美元。其训练费用相比OpenAI的GPT-4等目前全球主流的大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
DeepSeek“AI界拼多多”也由此得名。
DeepSeek-V3通过数据与算法层面的优化,大幅提升算力利用效率,实现了协同效应。在大规模MoE模型的训练中,DeepSeek-V3采用了高效的负载均衡策略、FP8混合精度训练框架以及通信优化等一系列优化措施,显著降低了训练成本,以及通过优化MoE专家调度、引入冗余专家策略、以及通过长上下文蒸馏提升推理性能。这证明,模型效果不仅依赖于算力投入,即使在硬件资源有限的情况下,依托数据与算法层面的优化创新,仍然可以高效利用算力,实现较好的模型效果。
广发证券分析称,DeepSeek-V3算力成本降低的原因有两点。
第一,DeepSeek-V3采用的DeepSeekMoE是通过参考了各类训练方法后优化得到的,避开了行业内AI大模型训练过程中的各类问题。
第二,DeepSeek-V3采用的MLA架构可以降低推理过程中的kv缓存开销,其训练方法在特定方向的选择也使得其算力成本有所降低。
科技媒体Maginative的创始人兼主编Chris McKay对此评论称,对于人工智能行业来说,DeepSeek-V3代表了一种潜在的范式转变,即大型语言模型的开发方式。这一成就表明,通过巧妙的工程和高效的训练方法,可能无需以前认为必需的庞大计算资源,就能实现人工智能的前沿能力。
他还表示,DeepSeek-V3的成功可能会促使人们重新评估人工智能模型开发的既定方法。随着开源模型与闭源模型之间的差距不断缩小,公司可能需要在一个竞争日益激烈的市场中重新评估他们的策略和价值主张。
不过,广发证券分析师认为,算力依然是推动大模型发展的核心驱动力。DeepSeek-V3的技术路线得到充分验证后,有望驱动相关AI应用的快速发展,应用推理驱动算力需求增长的因素也有望得到增强。尤其在实际应用中,推理过程涉及到对大量实时数据的快速处理和决策,仍然需要强大的算力支持。
在DeepSeek-V3刷屏之际,有一个bug也引发热议。
在试用DeepSeek-V3过程中,《每日经济新闻》记者在对话框中询问“你是什么模型”时,它给出了一个令人诧异的回答:“我是一个名为ChatGPT的AI语言模型,由OpenAl开发。”此外,它还补充说明,该模型是“基于GPT-4架构”。
国内外很多用户也都反映了这一现象。而且,12月27日,Sam Altman发了一个帖文,外媒指出,Altman这篇推文意在暗讽其竞争对手对OpenAI数据的挖掘。
于是,有人就开始质疑:DeepSeek-V3是否是在ChatGPT的输出基础上训练的?为此,《每日经济新闻》向深度求索发出采访请求。截至发稿,尚未收到回复。
针对这种情况产生的原因,每经记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示,他对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得了改进。”
TechCrunch则猜测称,深度求索可能用了包含GPT-4通过ChatGPT生成的文本的公共数据集。“如果DeepSeek-V3是用这些数据进行训练的,那么该模型可能已经记住了GPT-4的一些输出,现在正在逐字反刍它们。”
“显然,该模型(DeepSeek-V3)可能在某些时候看到了ChatGPT的原始反应,但目前尚不清楚从哪里看到的,”伦敦国王学院专门研究人工智能的研究员Mike Cook也指出,“这也可能是个‘意外’。”他进一步解释称,根据竞争对手AI系统输出训练模型的做法可能对模型质量产生“非常糟糕”的影响,因为它可能导致幻觉和误导性答案。
不过,DeepSeek-V3也并非是第一个错误识别自己的模型,谷歌的Gemini等有时也会声称是竞争模型。例如,Gemini在普通话提示下称自己是百度的文心一言聊天机器人。
造成这种情况的原因可能在于,AI公司在互联网上获取大量训练数据,但是,现如今的互联网本就充斥着各种各样用AI生产出来的数据。据外媒估计,到2026年,90%的互联网数据将由AI生成。这种 “污染” 使得从训练数据集中彻底过滤AI输出变得相当困难。
“互联网数据现在充斥着AI输出,”非营利组织AI Now Institute的首席AI科学家Khlaaf表示,基于此,如果DeepSeek部分使用了OpenAI模型进行提炼数据,也不足为奇。
】【2021年最香游戏—《超激斗梦境》,你绝对不能错过!******
是什么原因让玩家狂热地爱上一款游戏?大部分是因为这款游戏会让人越来越上头,哎!真香~
超神酷炫的动作释放技能、精美细腻的场景塑造所带来的沉浸式刷图体验,是吸引玩家的第一步。而持续不断地创新性玩法与人物技能装备塑造则是打开真香的持久方式,网易自研的2.5D俯视角端游《超激斗梦境》被称作为2021“真香”游戏,它的出现,绝对会蚕食你的无聊时光。

为什么说他真香呢?首先从“2.5D视角诠释刷图游戏的新真谛”开始,2.5D俯视角画面给人更真实的打斗感受,画面可以容纳更多的动作特效,走位也更加自由,不仅不会像3D那么晕还提高了动作刷感,无论是技能动作特效还是刷图体验,都上升了一个阶段。


《超激斗梦境》不仅在画面上提升整体视觉效果,更是突破平庸的打怪刷图,在人物技能上增加了很多新奇有趣的技能玩法。有操控影子的法师—灰羽,持剑走天下的剑士—詹姆斯,格斗家—薇格,枪械手—芙兰,辅助—海洋公主妮可等多个人物,他们每个人都拥有2个可转职方向,每个人物都拥有至少20种技能,且每个技能都能让人眼前一亮,比如妮可,她的技能是可以随时召唤巨鲸、龙卷风等,技能操作顺滑流畅,视觉更是劲爆美绝,可辅助可战斗,异世界里辅助扛把子一手!


除了视觉画面和人物技能,游戏在地图场景与玩法上也下了功夫。几百张地图,各个地图都有不同的玩法,你可以在这里玩机甲战士、开飞车、骑白虎、上天遁地、和蜘蛛斗智斗勇等等等,体验各类创意玩法才是《超激斗梦境》的真香体质本质。不局限于刷图,但是比单纯打怪更有意思,这也是为什么很多内测玩家会玩下去并愿意分享的原因。只为好玩而玩,才是游戏的本质。



真香游戏如一杯茶,入口微苦,回味甘甜,越品越香。而《超激斗梦境》则是真香中的上品,目前已经在公测预约阶段了!赶快去官网预约一波吧!
】【刷屏的DeepSeek******
每经记者 郑雨航 每经编辑 高涵 兰素英
“DeepSeek-V3超越了迄今为止所有开源模型。”这是国外独立评测机构Artificial Analysis测试了DeepSeek-V3后得出的结论。
12月26日,深度求索官方微信公众号推文称,旗下全新系列模型DeepSeek-V3首个版本上线并同步开源。
公众号推文是这样描述的:DeepSeek-V3为自研MoE模型,671B参数,激活37B,在14.8T token上进行了预训练。DeepSeek-V3多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。
不过,广发证券发布的测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。
更重要的是,深度求索使用英伟达H800 GPU在短短两个月内就训练出了DeepSeek-V3,仅花费了约558万美元。其训练费用相比GPT-4等大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
消息一出,引发了海外AI圈热议。OpenAI创始成员Karpathy甚至对此称赞道:“DeepSeek-V3让在有限算力预算上进行模型预训练这件事变得容易。DeepSeek-V3看起来比Llama-3-405B更强,训练消耗的算力却仅为后者的1/11。”
然而,在使用过程中,《每日经济新闻》记者发现,DeepSeek-V3竟然声称自己是ChatGPT。一时间,“DeepSeek-V3是否在使用ChatGPT输出内容进行训练”的质疑声四起。
对此,《每日经济新闻》记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得改进。”
每经记者向深度求索公司发出采访请求,截至发稿,尚未收到回复。
针对DeepSeek-V3,独立评测网站Artificial Anlaysis就关键指标——包括质量、价格、性能(每秒生成的Token数以及首个Token生成时间)、上下文窗口等多方面——与其他人工智能模型进行对比,最终得出以下结论。
质量:DeepSeek-V3质量高于平均水平,各项评估得出的质量指数为80。
价格:DeepSeek-V3比平均价格更便宜,每100万个Token的价格为0.48美元。其中,输入Token价格为每100万个Token 0.27美元,输出Token价格为每100万个Token1.10 美元。
速度:DeepSeek-V3比平均速度慢,其输出速度为每秒87.5个Token。
延迟:DeepSeek-V3与平均水平相比延迟更高,接收首个Token(即首字响应时间)需要1.14秒。
上下文窗口:DeepSeek-V3的上下文窗口比平均水平小,其上下文窗口为13万个Token。
最终Artificial Anlaysis得出结论:
“DeepSeek-V3模型超越了迄今为止发布的所有开放权重模型,并且击败了OpenAI的GPT-4o(8月),并接近Anthropic的Claude 3.5 Sonnet(10月)。
DeepSeek-V3的人工智能分析质量指数得分为80,领先于OpenAI的GPT-4o和Meta的Llama 3.3 70B等模型。目前唯一仍然领先于DeepSeek的模型是谷歌的Gemini 2.0 Flash和OpenAI的o1系列模型。领先于阿里巴巴的Qwen2.5 72B,DeepSeek现在是中国的AI领先者。”
12月29日广发证券计算机行业分析师发布研报称:“为了深入探索DeepSeek-V3的能力,我们采用了覆盖逻辑、数学、代码、文本等领域的多个问题对模型进行测试,将其生成结果与豆包、Kimi以及通义千问大模型生成的结果进行比较。”
测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。例如,在密文解码任务中,DeepSeek-V3是唯一给出正确答案的大模型;而在代码生成的任务中,DeepSeek-V3给出的代码注释、算法原理解释以及开发流程的指引是最为全面的。在文本生成和数学计算能力方面,DeepSeek-V3并未展现出明显优于其他大模型之处。
除了能力,DeepSeek-V3最让业内惊讶的是它的低价格和低成本。
《每日经济新闻》记者注意到,亚马逊Claude 3.5 Sonnet模型的API价格为每百万输入tokens 3美元、输出15美元。也就是说,即便是不按照优惠价格,DeepSeek-V3的使用费用也几乎是Claude 3.5 Sonnet的五十三分之一。
相对低廉的价格,得益于DeepSeek-V3的训练成本控制,深度求索在短短两个月内使用英伟达H800 GPU数据中心就训练出了DeepSeek-V3模型,花费了约558万美元。其训练费用相比OpenAI的GPT-4等目前全球主流的大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
DeepSeek“AI界拼多多”也由此得名。
DeepSeek-V3通过数据与算法层面的优化,大幅提升算力利用效率,实现了协同效应。在大规模MoE模型的训练中,DeepSeek-V3采用了高效的负载均衡策略、FP8混合精度训练框架以及通信优化等一系列优化措施,显著降低了训练成本,以及通过优化MoE专家调度、引入冗余专家策略、以及通过长上下文蒸馏提升推理性能。这证明,模型效果不仅依赖于算力投入,即使在硬件资源有限的情况下,依托数据与算法层面的优化创新,仍然可以高效利用算力,实现较好的模型效果。
广发证券分析称,DeepSeek-V3算力成本降低的原因有两点。
第一,DeepSeek-V3采用的DeepSeekMoE是通过参考了各类训练方法后优化得到的,避开了行业内AI大模型训练过程中的各类问题。
第二,DeepSeek-V3采用的MLA架构可以降低推理过程中的kv缓存开销,其训练方法在特定方向的选择也使得其算力成本有所降低。
科技媒体Maginative的创始人兼主编Chris McKay对此评论称,对于人工智能行业来说,DeepSeek-V3代表了一种潜在的范式转变,即大型语言模型的开发方式。这一成就表明,通过巧妙的工程和高效的训练方法,可能无需以前认为必需的庞大计算资源,就能实现人工智能的前沿能力。
他还表示,DeepSeek-V3的成功可能会促使人们重新评估人工智能模型开发的既定方法。随着开源模型与闭源模型之间的差距不断缩小,公司可能需要在一个竞争日益激烈的市场中重新评估他们的策略和价值主张。
不过,广发证券分析师认为,算力依然是推动大模型发展的核心驱动力。DeepSeek-V3的技术路线得到充分验证后,有望驱动相关AI应用的快速发展,应用推理驱动算力需求增长的因素也有望得到增强。尤其在实际应用中,推理过程涉及到对大量实时数据的快速处理和决策,仍然需要强大的算力支持。
在DeepSeek-V3刷屏之际,有一个bug也引发热议。
在试用DeepSeek-V3过程中,《每日经济新闻》记者在对话框中询问“你是什么模型”时,它给出了一个令人诧异的回答:“我是一个名为ChatGPT的AI语言模型,由OpenAl开发。”此外,它还补充说明,该模型是“基于GPT-4架构”。
国内外很多用户也都反映了这一现象。而且,12月27日,Sam Altman发了一个帖文,外媒指出,Altman这篇推文意在暗讽其竞争对手对OpenAI数据的挖掘。
于是,有人就开始质疑:DeepSeek-V3是否是在ChatGPT的输出基础上训练的?为此,《每日经济新闻》向深度求索发出采访请求。截至发稿,尚未收到回复。
针对这种情况产生的原因,每经记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示,他对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得了改进。”
TechCrunch则猜测称,深度求索可能用了包含GPT-4通过ChatGPT生成的文本的公共数据集。“如果DeepSeek-V3是用这些数据进行训练的,那么该模型可能已经记住了GPT-4的一些输出,现在正在逐字反刍它们。”
“显然,该模型(DeepSeek-V3)可能在某些时候看到了ChatGPT的原始反应,但目前尚不清楚从哪里看到的,”伦敦国王学院专门研究人工智能的研究员Mike Cook也指出,“这也可能是个‘意外’。”他进一步解释称,根据竞争对手AI系统输出训练模型的做法可能对模型质量产生“非常糟糕”的影响,因为它可能导致幻觉和误导性答案。
不过,DeepSeek-V3也并非是第一个错误识别自己的模型,谷歌的Gemini等有时也会声称是竞争模型。例如,Gemini在普通话提示下称自己是百度的文心一言聊天机器人。
造成这种情况的原因可能在于,AI公司在互联网上获取大量训练数据,但是,现如今的互联网本就充斥着各种各样用AI生产出来的数据。据外媒估计,到2026年,90%的互联网数据将由AI生成。这种 “污染” 使得从训练数据集中彻底过滤AI输出变得相当困难。
“互联网数据现在充斥着AI输出,”非营利组织AI Now Institute的首席AI科学家Khlaaf表示,基于此,如果DeepSeek部分使用了OpenAI模型进行提炼数据,也不足为奇。
】人气软件
-

厨艺大师 56.62 MB
/简体中文 -

太空侵略者:报复 逆袭的太空侵略者 562.57 MB
/简体中文 -

神泣战争 873.52 MB
/简体中文 -

猎魔人 73.24 MB
/简体中文 -

多彩滚球 226.99 MB
/简体中文 -

超级精灵球 715.15 MB
/简体中文 -
肉球大乱斗 16.68 MB
/简体中文 -

再战 867.31 MB
/简体中文 -

波斯王子:继承人 966.38 MB
/简体中文 -

小美人鱼 38.91 MB
/简体中文 -

足球大师 44.18 MB
/简体中文 -

猎人来了我怕怕 449.56 MB
/简体中文 -

胜负师传说 哲也:苏醒传说 83.59 MB
/简体中文 -

分手回避 463.17 MB
/简体中文 -

最终庇护所 969.58 MB
/简体中文 -

探险家多拉:超级间谍 55.57 MB
/简体中文 -

机兽新世纪:冲刺 31.11 MB
/简体中文 -

秋之回忆 46.99 MB
/简体中文 -
分裂细胞:明日潘多拉 152.59 MB
/简体中文 -

全民蛇蛇 71.74 MB
/简体中文 -
无双乱舞 32.47 MB
/简体中文 -

使魔计划 241.99 MB
/简体中文 -

连系音乐! Gunpey重生 737.81 MB
/简体中文 -

歌星 43.11 MB
/简体中文 -

动物之斗-Solo Edition 87.75 MB
/简体中文 -

精灵之息:四色齿轮 479.58 MB
/简体中文 -

风云天下OL 495.44 MB
/简体中文 -

我的坦克 84.43 MB
/简体中文 -

神兵玄奇OL 295.48 MB
/简体中文 -

正义街道儿 38.22 MB
/简体中文 -

不败OL 967.29 MB
/简体中文 -

倾世情缘 714.93 MB
/简体中文 -
陆战雄狮 21.71 MB
/简体中文 -

天战 77.43 MB
/简体中文 -
伊甸领域 344.67 MB
/简体中文 -

无限试驾 147.77 MB
/简体中文 -
Arcade Archives Renegade 516.22 MB
/简体中文 -

魔王召唤 42.98 MB
/简体中文 -

方块城堡 126.56 MB
/简体中文 -

烈焰裁决 41.16 MB
/简体中文 -

沙滩排球OL 39.77 MB
/简体中文 -

魔法连萌 85.43 MB
/简体中文 -
王者魔神 488.53 MB
/简体中文 -

空岛幻想H5 177.18 MB
/简体中文 -

职业棒球大联盟2006 319.15 MB
/简体中文 -

合成喵喵丸 585.34 MB
/简体中文 -

迷你英雄:超越无限 31.39 MB
/简体中文 -

部落世界 17.85 MB
/简体中文 -
萌坦大作战 188.98 MB
/简体中文 -
铁血坦克 855.66 MB
/简体中文 -

植物大战僵尸:花园战争 937.21 MB
/简体中文 -
死亡日记-首款末日求生游戏 38.33 MB
/简体中文 -

明星保卫战 29.97 MB
/简体中文 -

旅行会话指南DS:DS系列5 美国 389.57 MB
/简体中文 -
永远的提尔纳诺 77.56 MB
/简体中文 -

力量与荣耀OL 417.19 MB
/简体中文 -

火焰之纹章无双 942.86 MB
/简体中文 -

疯西游OL 22.65 MB
/简体中文 -

英雄无敌之魔卡联盟 57.83 MB
/简体中文 -

浮线对战 595.37 MB
/简体中文 -
女神奇迹之力 19.91 MB
/简体中文 -

命令与征服:宿敌 95.92 MB
/简体中文 -

森林狩猎 916.12 MB
/简体中文 -

家庭教师 Hitman Reborn!DS 开炎 指环争夺战! 57.61 MB
/简体中文 -

三国战神(威力加强版) 958.64 MB
/简体中文 -

街机金蟾捕鱼 674.27 MB
/简体中文 -

刀客剑心 271.17 MB
/简体中文 -

SSR三国 43.82 MB
/简体中文 -

霸OL 91.42 MB
/简体中文 -

极品醉车:消除器 418.11 MB
/简体中文 -

大圣外传 26.41 MB
/简体中文 -

泰戈·伍兹高尔夫PGA巡回赛2008 652.89 MB
/简体中文 -

像素僵尸射击 911.51 MB
/简体中文 -

捉迷藏大作战 73.43 MB
/简体中文 -

Blitz2 11.21 MB
/简体中文 -

魔导旅团 721.65 MB
/简体中文 -

NBA街头篮球主场 91.98 MB
/简体中文 -

剧本杀小镇 536.29 MB
/简体中文 -

山海经 363.59 MB
/简体中文 -

地狱男爵:恶魔科学 56.59 MB
/简体中文 -

空姬ACE VIRGIN:银翼的战斗姬 34.88 MB
/简体中文 -

奇迹天下 19.98 MB
/简体中文 -

影子大乱斗 88.98 MB
/简体中文 -
仙灵奇缘 465.42 MB
/简体中文 -
灵光守护者 878.43 MB
/简体中文 -
耻辱:布瑞格摩尔的女巫 739.87 MB
/简体中文 -

思乡之风 71.71 MB
/简体中文 -

苍天劫 889.27 MB
/简体中文 -
暴走皮卡丘 184.52 MB
/简体中文 -

劲爆美式橄榄球2004 545.89 MB
/简体中文 -

黄金骑士 94.51 MB
/简体中文 -

荣誉勋章:天降神兵 725.13 MB
/简体中文 -
SuperLite2500 激辣数独2500问 53.45 MB
/简体中文 -
G型神探:高级任务 33.79 MB
/简体中文 -

天堂战记 837.74 MB
/简体中文 -

赤壁三国ol 812.61 MB
/简体中文 -

Berkanix 963.53 MB
/简体中文 -

Project Aurora 68.86 MB
/简体中文 -

末代侠客 418.15 MB
/简体中文
新闻相关
-

25年006期铁人铁胆3d试机号后分析 83.19 MB
/简体中文 -

轻松冒险不伤肝,《九畿:岐风之旅》辰极纪测试今日开启 452.69 MB
/简体中文 -

战争帮派模拟器游戏下载 65.39 MB
/简体中文 -

组装车间官宣,维克斯Mk3将加入《坦克世界》 541.73 MB
/简体中文 -
神奇的横冲直撞手游下载 77.24 MB
/简体中文 -

《月圆之夜》ChinaJoy展台落幕,S4.5全新版本上线对决 22.61 MB
/简体中文 -

逗斗火柴人国际服最新版下载2021 33.58 MB
/简体中文 -
p3字汇总 25006期 超级马克p3字谜总汇 84.67 MB
/简体中文 -

问灵巫《一梦江湖》暑期资料片携全套清凉福利绝美来袭 89.37 MB
/简体中文 -

2024年全年全国居民消费价格比上年上涨0.2% 525.58 MB
/简体中文 -
九游剑网1归来手游下载 955.45 MB
/简体中文 -

果盘霸气英雄送gm1版下载 99.59 MB
/简体中文 -

双色球2025003期开机号分析(附历史) 12.79 MB
/简体中文 -
童心不改 来《问道》中洲欢度六一 491.69 MB
/简体中文 -
嘉年华流程全面简化,长安穿越指南第一弹来袭 976.72 MB
/简体中文 -

双色球历史上的今天003期 65.19 MB
/简体中文 -
![双色球25年003期期[黑蝴蝶]本期看好一码围蓝](http://www.www.m.jnyfsp.com/uploads/images/1809580.jpg)
双色球25年003期期[黑蝴蝶]本期看好一码围蓝 244.88 MB
/简体中文 -

6到飞起,《英魂之刃口袋版》66节狂送皮肤与英雄 657.49 MB
/简体中文 -

2024《英魂之刃口袋版》精英联赛夏季赛决赛即将打响 88.89 MB
/简体中文 -
天使永久区官方版下载 823.17 MB
/简体中文 -

秦时明月和铠甲勇士拍电影,国产第一IP宇宙击破多厨次元壁 321.99 MB
/简体中文 -

《第五人格》二十四节气演绎录芒种篇线下活动回顾 46.94 MB
/简体中文 -

少前云图计划taptap客户端下载 27.82 MB
/简体中文 -

火力支援已就位,《战舰世界》拍卖行今日开启 462.72 MB
/简体中文 -

《英魂之刃口袋版》66节送英雄皮肤,S31赛季携免费新装等你来战 16.62 MB
/简体中文 -
小军图25006期赢钱快报天玄报 993.66 MB
/简体中文 -
格斗王者世界官方版下载 46.54 MB
/简体中文 -

增能菲戈首登绿茵,右路天尊传中大师降临 898.76 MB
/简体中文 -

《剑网3缘起》挑战难度血战天策即将开启 13.74 MB
/简体中文 -
![福彩3D2025年006期[十万火]精解太湖钓叟 仨肉丸](http://www.www.m.jnyfsp.com/uploads/images/5331630.jpg)
福彩3D2025年006期[十万火]精解太湖钓叟 仨肉丸 598.94 MB
/简体中文 -

仙山百宝现,《问道》电脑版百宝翻牌活动限时开启 759.47 MB
/简体中文 -

百度猫和老鼠手游下载 971.16 MB
/简体中文 -

以拳力赴波涛,《战舰世界》SNK联动正式开启 648.89 MB
/简体中文 -

激情盛夏,英雄汇聚 《剑网2》725五绝争霸赛事来袭 91.53 MB
/简体中文 -

《远征OL》联动《饿了么》今日开启美食节新区饕餮 45.52 MB
/简体中文 -

好玩的策略并不贵,《世界启元》引领SLG进入新时代 126.63 MB
/简体中文 -

神仙联动 童趣来袭 《剑网3缘起》×《非人哉》邀你一起过六一 27.31 MB
/简体中文 -

掠夺之剑暗影大陆中文版下载 68.19 MB
/简体中文 -
最小成本培养换取极致收益,《天下》手游元魂珠培养攻略来袭 61.17 MB
/简体中文 -

流星群侠传虫虫助手版下载 662.49 MB
/简体中文 -
“智慧成长,安全先行”边锋网络携手各界共同引领青春航道 262.17 MB
/简体中文 -

哪吒汽车CEO被限制高消费 958.31 MB
/简体中文 -
2023年155期3d图迷汇总(六) 947.16 MB
/简体中文 -

《模拟城市:我是市长》繁星夏梦版本登陆苹果AppStore 37.27 MB
/简体中文 -
中龙图25006期福寿禄八卦图三意图迷 719.36 MB
/简体中文 -

最后的原始人九游版下载 284.31 MB
/简体中文 -

SP遥念烟烟罗降临,式神召唤动画欣赏 43.25 MB
/简体中文 -

逍遥游一刀武林手游下载 97.54 MB
/简体中文 -

胜利女神:新的希望官网在哪下载 最新官方下载安装地址 374.99 MB
/简体中文 -

2025006期齐齐哈尔市当期P3北京谜语 38.94 MB
/简体中文 -

《狙击手冠军》即将上线,精彩玩法曝光 98.23 MB
/简体中文 -
天涯明月刀OL夏季资料片《有凤来仪》上线,携全民福利破世登场 348.59 MB
/简体中文 -

火速集合,营救爷爷《葫芦娃:奇幻世界》如意测试今日开启 767.23 MB
/简体中文 -

25年006期福彩詹天佑3D点评分析 91.15 MB
/简体中文 -
过肩摔大作战最新版下载 59.86 MB
/简体中文 -

热血沙城红包版手游下载 472.14 MB
/简体中文 -

新手必看,魔域口袋版最速新人上手攻略 55.35 MB
/简体中文 -

终焉誓约国际服游戏下载 522.69 MB
/简体中文 -

2024年ChinaJoy拉开帷幕,影核携两款全新力作荣耀登台 558.27 MB
/简体中文 -
006期天齐网解本期太湖字谜钓叟 362.93 MB
/简体中文 -

蛋仔滑滑开启全新快三消经营体验,乐邀玩家进入“蛋”宇宙 21.96 MB
/简体中文 -

人民日报尺素金声:对编造、传播股市谣言坚决说不 698.42 MB
/简体中文 -

保送新手14天,魔域口袋版新手攻略一篇看懂 519.12 MB
/简体中文 -

25年006期3d试机号后黑圣手一语定号 224.88 MB
/简体中文 -

《狙击手冠军》真实靶场体验,挑战你的射击极限 192.55 MB
/简体中文 -

未来钢铁侠绳索英雄最新版下载 67.18 MB
/简体中文 -

熠熠生辉,《第五人格》击球手限时稀世时装礼包即将上架 188.12 MB
/简体中文 -
新手必看,魔域口袋版最速新人上手攻略 132.26 MB
/简体中文 -
《英魂之刃口袋版》66节送英雄皮肤,S31赛季携免费新装等你来战 81.68 MB
/简体中文 -

代言人大鹏:来大话交个新“鹏”友,去专属新服玩个痛快 781.52 MB
/简体中文 -

《朝歌》手游X动画电影《二郎神之深海蛟龙》联动即将来袭 56.62 MB
/简体中文 -

《崩坏星穹铁道》记忆开拓者养成攻略 记忆开拓者怎么培养 27.77 MB
/简体中文 -

风云岛行动官方下载最新版 61.39 MB
/简体中文 -

国产最强射击竞技,腾讯今日出手王牌 85.32 MB
/简体中文 -

006期福彩3D历史开奖号码统计表 367.84 MB
/简体中文 -
2025年006期3d图迷汇总(三) 79.96 MB
/简体中文 -

预约《剑侠世界端游》新服送百万绑金,领白秋琳同伴 758.69 MB
/简体中文 -

《远征OL》十五周年一路有你,新区十五周年专享万元豪礼 29.22 MB
/简体中文 -

武林传说2官方版下载 672.21 MB
/简体中文 -

《永劫无间》定胜终测开启,首发游戏Copilot智能AI队友功能 24.43 MB
/简体中文 -

233d155期碎玉跨度字迷 398.57 MB
/简体中文 -

25年006期3D专家解今日太湖字谜汇总(天齐网整理汇总) 93.21 MB
/简体中文 -

Steam首届Furry游戏节,这款国产射击游戏脱颖而出 752.66 MB
/简体中文 -

《高能英雄》S5新版本正式开启,集结新地图续写高能之旅 91.27 MB
/简体中文 -

25年006期3d启机开机号+夏兰{边城金码} 33.26 MB
/简体中文 -

《月圆之夜》S4团建第二战来袭,看主播再度对决 486.66 MB
/简体中文 -
盛夏新篇,精彩升级《第五人格》暑期前瞻直播回顾 24.65 MB
/简体中文 -
李斯特菌的传说手游下载 784.43 MB
/简体中文 -

《黑光生存进化》今日开启预约,虚幻5引擎革新游戏体验 75.14 MB
/简体中文 -

天魄拆卸功能上线两种方式任君选择,海量福利等你来 266.51 MB
/简体中文 -

拳皇英雄传说内测版下载 73.96 MB
/简体中文 -

机器人建筑大师手机版下载 821.98 MB
/简体中文 -

25年008期双色球红谷子玄机诗谜 55.36 MB
/简体中文 -
![双色球25年003期[常领]五行走势图分析](http://www.www.m.jnyfsp.com/uploads/images/3765250.jpg)
双色球25年003期[常领]五行走势图分析 533.56 MB
/简体中文 -

《模拟城市:我是市长》即将迎来繁星夏梦版本 256.24 MB
/简体中文 -

《圣斗士星矢:重生2》斗士档案人气圣斗士公布(第一期) 768.38 MB
/简体中文 -

八载同行,《FGO》简中版八周年庆典狂欢今日正式启动 32.24 MB
/简体中文 -

增能阿尔贝蒂尼首次亮相,红黑队副掌控节拍统领全局 399.17 MB
/简体中文 -

3d23155期胆红一句定三码 17.44 MB
/简体中文 -

齐天大圣登录送,《球球大作战》闪击战端午放粽爽玩 233.78 MB
/简体中文 -

《放开那三国2》槃金武将携新时装今日更新 46.88 MB
/简体中文 -

点灯人手机版官方下载 547.17 MB
/简体中文 -

《御龙在天手游》国战主播招募,10万金子千元奖金一起拿 275.56 MB
/简体中文 -

《闪耀暖暖》非凡感应活动“古木的礼赞” “菇菇乐园”福利活动开启 62.65 MB
/简体中文 -
黑神话悟空云游戏云电脑高清在线玩教程公布 228.38 MB
/简体中文 -
轻松冒险不伤肝,《九畿:岐风之旅》辰极纪测试今日开启 625.83 MB
/简体中文 -
狂欢倒计时,《暗黑破坏神:不朽》两周年庆典蓄势待发 158.23 MB
/简体中文 -

25年003期双色球峨嵋道姑预测诗 16.97 MB
/简体中文 -

全团一起拼大奖,魔域口袋版全新无极斗界上线 25.25 MB
/简体中文 -
逍遥游一刀武林手游下载 62.77 MB
/简体中文 -
人民日报尺素金声:对编造、传播股市谣言坚决说不 33.46 MB
/简体中文 -

赛尔号超级英雄百度版下载 78.92 MB
/简体中文 -

双色球25年003期天吉龙头凤尾鸟语断蓝图 541.88 MB
/简体中文 -

燃烧吧航海王满v公益服下载 78.13 MB
/简体中文 -
《闪耀暖暖》非凡感应活动“古木的礼赞” “菇菇乐园”福利活动开启 644.59 MB
/简体中文 -

白熊猫25年003期双色球杀两枚红球图谜 21.59 MB
/简体中文 -

25006期北京3d试机号后谜语总汇 19.28 MB
/简体中文 -

《放开那三国3》四周年庆典服开启 948.64 MB
/简体中文 -

九游奇幻祖玛手游下载 788.29 MB
/简体中文 -

双色球第25004期大队书记最新段位诗谜又一篇 28.58 MB
/简体中文 -

武炼巅峰之武道官方版下载 632.77 MB
/简体中文 -

盛夏时节科幻主题大冒险,《碧蓝航线》参展BW2024精彩回顾 174.72 MB
/简体中文 -

首批中央救灾物资已运抵西藏日喀则地震灾区 91.51 MB
/简体中文 -
趣玩成语官网在哪下载 最新官方下载安装地址 28.66 MB
/简体中文 -
《黑光生存进化》今日开启预约,虚幻5引擎革新游戏体验 148.91 MB
/简体中文 -
玄机千变,《剑侠世界3》新版本新玩法攻略公布 771.91 MB
/简体中文 -

元素大天使官方版下载 84.64 MB
/简体中文 -

夏日颜值盛典全民征集开启,永久时装0元带走 33.82 MB
/简体中文 -

25年006期3d试机号后晚秋一语看奖号 73.14 MB
/简体中文 -

复仇英雄格斗游戏下载 66.68 MB
/简体中文 -

单机联网成功破壁,《燕云十六声》是如何实现“既要又要”的 13.97 MB
/简体中文 -

网易Y3高校赛夏令营开启,拿到offer的大学生们要搞事情啦 57.11 MB
/简体中文 -

PV首曝,魔域口袋版花魁盛宴即将拉开序幕 12.88 MB
/简体中文 -

《问道》电脑版7月破阵探宝活动全版本开启 819.75 MB
/简体中文 -

《天下》手游8周年资料片庆今朝7月31日狂欢来袭 112.26 MB
/简体中文 -

23年155期福彩3D模拟开奖号码+详细分析 868.93 MB
/简体中文 -
装甲战斗之王游戏下载 33.89 MB
/简体中文 -
25年006期3d启机开机号+夏兰{边城金码} 23.73 MB
/简体中文 -

异兽大冒险4399版下载 99.17 MB
/简体中文 -

25006期真黑圣手3D今日字谜 83.97 MB
/简体中文 -

前哨直播精彩不断《FGO》8周年庆典活动即将盛大开幕 94.23 MB
/简体中文 -

23155期真黑圣手3D今日字谜 37.96 MB
/简体中文 -

超级英雄队长手游下载 577.35 MB
/简体中文 -

火柴人格斗吧2官方版下载 786.78 MB
/简体中文 -

【墨韵】第五人格×中国美术学院共创课题回顾 64.21 MB
/简体中文 -

《模拟城市:我是市长》逍遥红尘欢乐建筑曝光 25.43 MB
/简体中文 -

goddess魔剑契约手机版下载 92.27 MB
/简体中文 -
《问道》经典版新服“二〇二四”正式定档,抢注活动现已开启 91.25 MB
/简体中文 -

《模拟城市:我是市长》夏日倾心限时活动即将登场 825.89 MB
/简体中文 -

牡丹怀旧服手机版下载 56.11 MB
/简体中文 -
元气骑士oppo版下载 557.86 MB
/简体中文 -

深耕精品,西山居亮相河南卫视,《剑网3》以舞传承诉忠肠 36.62 MB
/简体中文 -

《模拟城市:我是市长》明珠璀璨限时活动抢先看 447.68 MB
/简体中文 -

起源之战复仇官方下载 951.29 MB
/简体中文 -

《世界之外》“夏夜诡叙诗”版本上线,无限世界开启校园规则怪谈 621.91 MB
/简体中文 -

上海地铁站打破次元壁,小红书联动头部厂商开启“游戏这个夏天” 879.37 MB
/简体中文 -
狂欢倒计时,《暗黑破坏神:不朽》两周年庆典蓄势待发 29.97 MB
/简体中文 -

都是我小弟手机版下载 531.83 MB
/简体中文 -
![双色球25年003期[郑戈]本期新旧跳分析](http://www.www.m.jnyfsp.com/uploads/images/8386960.jpg)
双色球25年003期[郑戈]本期新旧跳分析 944.25 MB
/简体中文 -
![福彩3D2025年006期[智多星]破解太湖谜一碗汤](http://www.www.m.jnyfsp.com/uploads/images/1124640.jpg)
福彩3D2025年006期[智多星]破解太湖谜一碗汤 49.68 MB
/简体中文 -

双色球25年003期阳光探码+彩民乐图谜 33.17 MB
/简体中文 -

《模拟城市:我是市长》激情盛夏版本登陆苹果AppStore 66.75 MB
/简体中文 -

双色球23068期蝴蝶结一句杀蓝字谜 235.37 MB
/简体中文 -

25年006期福彩3D模拟开奖号码+详细分析 367.87 MB
/简体中文 -
超凡蜘蛛英雄游戏下载 584.85 MB
/简体中文 -

乐高星球大战破解版下载 29.87 MB
/简体中文 -
全国商务工作会议在京召开 888.12 MB
/简体中文 -

新门派玄机,《剑侠世界3》全新资料片6.12上线 248.13 MB
/简体中文 -
大魔法师旷野冒险,《剑与远征:启程》国区定档测试开启 342.24 MB
/简体中文 -
四大天王合体开唱?刘德华表态了 534.53 MB
/简体中文 -

九游飞跃自我手游下载 278.49 MB
/简体中文 -

《狙击手冠军》正式推出,享受冠军的射击盛宴 316.38 MB
/简体中文 -
现在还有夺金点,魔域口袋版火热夺魁中 72.41 MB
/简体中文 -

《碧蓝航线》2024港区盛夏清凉节深圳站精彩收官 85.37 MB
/简体中文 -

万元奢礼大派发,速来魔域口袋版 43.18 MB
/简体中文 -

《保卫要塞》阵容搭配,部队类型和编队推荐 74.86 MB
/简体中文 -

《侠客风云传OL》周年庆盛典来袭,海量福利邀您共赴江湖风云 979.45 MB
/简体中文 -
【墨韵】第五人格×中国美术学院共创课题回顾 72.33 MB
/简体中文 -

重回三族版本,免费版怀旧服815开启 117.56 MB
/简体中文 -
神仙联动 童趣来袭 《剑网3缘起》×《非人哉》邀你一起过六一 881.81 MB
/简体中文 -

烈火锻萃《第五人格》第三十三赛季精华3爆料来袭 52.17 MB
/简体中文 -
风云岛行动手游虫虫版下载 66.28 MB
/简体中文 -

橡皮擦掉落大逃杀游戏下载 69.28 MB
/简体中文 -
玄机千变,《剑侠世界3》新版本新玩法攻略公布 21.24 MB
/简体中文 -

25004期秋水仙子双色球七步定乾坤诗谜 57.51 MB
/简体中文 -
逗斗火柴人测试服下载2022 72.93 MB
/简体中文 -
《永劫无间》定胜终测开启,首发游戏Copilot智能AI队友功能 34.18 MB
/简体中文 -

天下CJ WORK,2024年Chinajoy大荒乐园等你来探秘 38.13 MB
/简体中文 -

23年155期武当玉女掌门一句定三码 417.57 MB
/简体中文 -

2023155期金胆王一语定金胆 128.23 MB
/简体中文 -

九游爆裂魔女手游下载 754.27 MB
/简体中文 -

弹射王九周年庆典火热来袭,更有超多周年福利等你来拿 436.98 MB
/简体中文 -

《西游:笔绘西行》出场角色牛魔王公布 87.61 MB
/简体中文 -
提前一年实现目标!零跑汽车2024年第四季度净利润转正 85.71 MB
/简体中文 -

《剑侠世界:起源》“古墓剑影”资料片6.20上线 37.41 MB
/简体中文 -

银币经验全都要 《战舰世界》登陆日行动终章到来 71.83 MB
/简体中文 -

《航海世纪》激爽夏日大作战,多项活动开启 644.96 MB
/简体中文 -

变形老虎机器人手机版下载 25.42 MB
/简体中文 -
爽剧剧情来袭,《失业了,我获得了亿万游戏财产》剧情猜测 13.75 MB
/简体中文 -

夏日炎炎,《第五人格》勘探员限时稀世时装礼包今日上线 615.64 MB
/简体中文 -
23年155期福彩3D模拟开奖号码+详细分析 16.16 MB
/简体中文 -
四大天王合体开唱?刘德华表态了 191.93 MB
/简体中文 -

全新花魁赛曝光,魔域口袋版年度玩家盛典即将上线 62.42 MB
/简体中文 -

《方舟生存飞升》夏日活动即将开启,“畸变”DLC九月上线 94.66 MB
/简体中文 -

2023年155期随缘而去跨迷 83.94 MB
/简体中文 -

《蛋仔滑滑》公测预约福利公布,《蛋仔派对》恐龙蛋套装免费送 54.97 MB
/简体中文 -
良心传奇风流霸业多职业版本下载 947.96 MB
/简体中文 -
小军图25006期赢钱快报天玄报 271.85 MB
/简体中文 -

《世界启元》定档7月16日,化身老中医专治SLG顽疾 12.43 MB
/简体中文 -

夏日狂欢来袭,《极限竞速:地平线5》享五折 94.84 MB
/简体中文 -

山海经之吞天妖兽最新版 95.85 MB
/简体中文 -
不休传说华为游戏下载 591.68 MB
/简体中文 -

良心不逼氪,SLG新游《三国:谋定天下》公测选区指南与武将推荐 27.76 MB
/简体中文 -
《天下》开天计划阶段性工作成果汇报 859.28 MB
/简体中文 -
年中重大版本盛大公测,魔域口袋版三大系统全新上线 62.77 MB
/简体中文 -

子弹慢慢飞最新版下载 32.11 MB
/简体中文 -

2024“打虎”超50名!反腐败持续高压力度不减 19.97 MB
/简体中文 -

25006期真精华布衣123456 643.53 MB
/简体中文 -

幻想大世界RPG《蓝色星原:旅谣》首次亮相Bilibili World 2024 16.31 MB
/简体中文 -

全服运动赢大奖,魔域口袋版8月卡诺萨运动会开幕 411.45 MB
/简体中文 -

争当风云人物,《剑侠世界:起源》“江湖名侠”开启报名 57.59 MB
/简体中文 -

侏罗纪生存岛屿手游下载 823.99 MB
/简体中文 -
单机联网成功破壁,《燕云十六声》是如何实现“既要又要”的 771.72 MB
/简体中文 -

抖音支付回应“注册资本增至31.5亿元”:有助于更稳健地开展业务 85.96 MB
/简体中文 -

暗潮涌动,《暗黑破坏神:不朽》四大全新魔神来袭 388.36 MB
/简体中文 -

25006期福彩中心开机号(附历史) 27.82 MB
/简体中文 -

《英魂之刃口袋版》66节庆典将落幕 航天主题皮肤闪耀登场 74.57 MB
/简体中文 -

25年006期3d试机号后牛魔王七字定码 44.51 MB
/简体中文 -

雾刃巡礼,《暗黑破坏神:不朽》2024ChinaJoy完美收官 42.28 MB
/简体中文 -
风云岛行动官方下载最新版 51.74 MB
/简体中文 -

复古至尊合击手游下载 742.78 MB
/简体中文 -

千锤百炼,天龙八部手游x棠溪宝剑非遗传承联动开启 63.97 MB
/简体中文 -

果盘武功来了手游下载 54.72 MB
/简体中文 -

25006期试机号3d今天专家联盟推荐双胆 46.17 MB
/简体中文 -

25年006期3d试机号后神算子定胆诗谜 97.23 MB
/简体中文 -

最新年兽直接送,魔域口袋版新服福利不容错过 549.59 MB
/简体中文 -

九游神火大陆手游下载 489.96 MB
/简体中文 -

植物球吃僵尸,《球球大作战》联动《植物大战僵尸2》开启 834.86 MB
/简体中文 -

绽樱烂漫,华梦浸香《阴阳师》本真三尾狐新皮肤即将上线 369.57 MB
/简体中文 -

滑进“蛋”宇宙,蛋仔IP超爽快三消经营手游《蛋仔滑滑》首曝 746.64 MB
/简体中文 -
夏日炎炎,《第五人格》勘探员限时稀世时装礼包今日上线 454.58 MB
/简体中文 -

组队打金一局暴富,《球球大作战》猎魔新玩法今日上线 849.31 MB
/简体中文 -
国风外观和橙武上线就送,夏日活动还有这么多重磅福利 97.79 MB
/简体中文 -
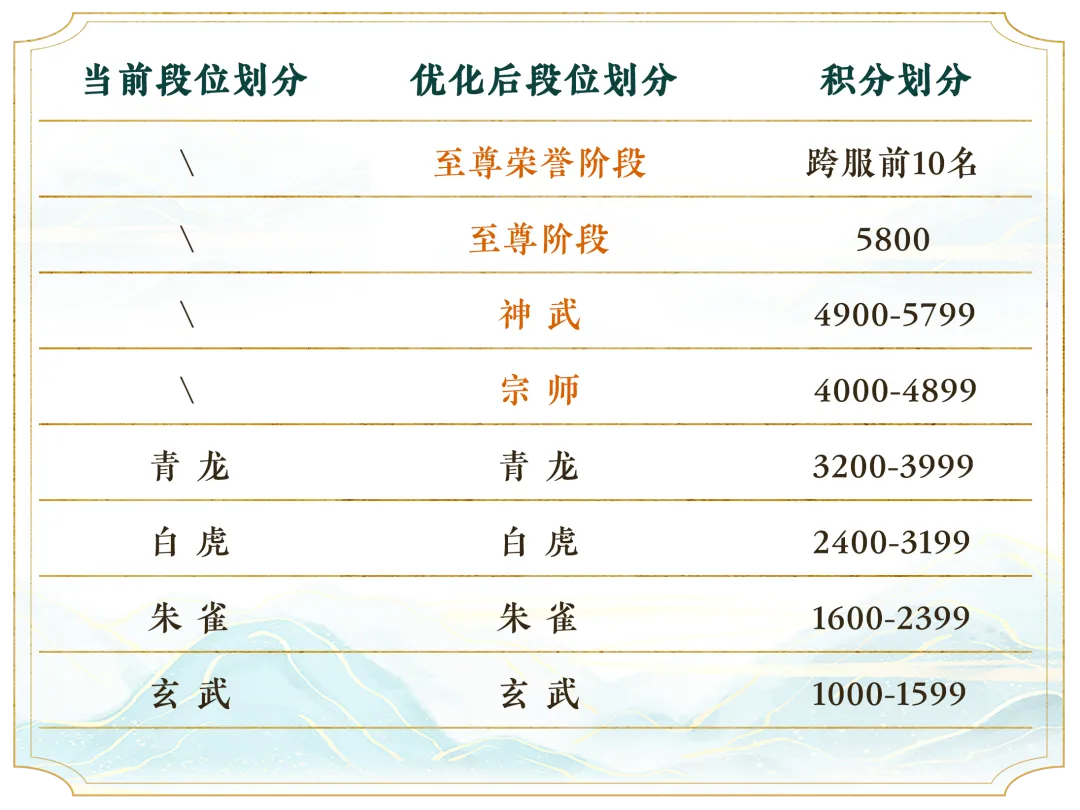
《天下》手游竞技场迭代开启,全新巅峰邀你角逐天下 683.14 MB
/简体中文 -
山海经之吞天妖兽最新版 78.95 MB
/简体中文 -
福彩3D2025年006期[十万火]精解太湖钓叟 仨肉丸 47.59 MB
/简体中文 -

《问道》时间版年度大服“甲辰”特色改版之玩法与活动 98.31 MB
/简体中文 -

历史上的今天双色球1月7日开奖号码汇总 97.28 MB
/简体中文 -

《坦克世界》1.25版本更新,诺曼底PvE模式开启 334.92 MB
/简体中文 -
《模拟城市:我是市长》繁星夏梦版本登陆苹果AppStore 269.87 MB
/简体中文 -

老爷子25年003期看双色球四蓝图谜 236.78 MB
/简体中文 -

职业再平衡,魔域口袋版11大职业全新加强 135.77 MB
/简体中文 -

双色球第25004期哥伦布今天一句杀蓝球 135.57 MB
/简体中文 -
超凡蜘蛛英雄游戏下载 87.11 MB
/简体中文 -
25年006期3d启机开机号+夏兰{边城金码} 246.27 MB
/简体中文 -
《远征OL》十五周年一路有你,新区十五周年专享万元豪礼 87.96 MB
/简体中文 -

逆水寒联手孔氏家庙,三击登科鼓为天下高考生祈福 912.79 MB
/简体中文 -

确定航线准备传送,星际迷航现已来到《战舰世界》 23.98 MB
/简体中文 -
2025003期天齐网今晚双色球字谜总汇 43.89 MB
/简体中文 -
组装车间官宣,维克斯Mk3将加入《坦克世界》 81.63 MB
/简体中文 -

因剑侠再相聚,《剑侠世界:起源》手游重现江湖情义 91.31 MB
/简体中文 -

超能英雄钢铁手游下载 14.39 MB
/简体中文 -
神奇的横冲直撞手游下载 18.97 MB
/简体中文 -

《蛋仔派对》全新刺激追逃玩法“逃出惊魂夜”恐怖来袭 78.89 MB
/简体中文 -

蛾影幢幢《第五人格》第三十三赛季精华2正式上线 76.38 MB
/简体中文 -

疾如雷电,《第五人格》求生者飞行家进阶攻略新鲜出炉 11.81 MB
/简体中文 -

天下手游选择玄溟教成为第十二个门派原因公布 63.88 MB
/简体中文 -
3d23155期胆红一句定三码 97.42 MB
/简体中文 -

体彩p32023年155期牛彩今日字谜汇总 33.18 MB
/简体中文 -

小小虎25006期炎黄子孙小小虎图迷 489.61 MB
/简体中文 -

三国天下统一游戏下载 16.16 MB
/简体中文 -
激情盛夏,英雄汇聚 《剑网2》725五绝争霸赛事来袭 29.83 MB
/简体中文 -

牛魔王25年003期杀两码红球图谜 15.26 MB
/简体中文 -

中国科学院院士、大连理工大学邱大洪教授逝世 35.34 MB
/简体中文 -
少前云图计划taptap客户端下载 29.46 MB
/简体中文 -
单机联网成功破壁,《燕云十六声》是如何实现“既要又要”的 33.12 MB
/简体中文 -
神仙联动 童趣来袭 《剑网3缘起》×《非人哉》邀你一起过六一 825.41 MB
/简体中文 -

25年006期P3晚秋(乙种和值)谜 15.78 MB
/简体中文 -
《模拟城市:我是市长》夏日倾心限时活动即将登场 97.74 MB
/简体中文 -
Steam首届Furry游戏节,这款国产射击游戏脱颖而出 574.57 MB
/简体中文 -

从困境中破而后立,《星球:重启》迎来真正的重启 353.82 MB
/简体中文 -

国产大飞机C919首次搭载旅客飞抵三亚 847.66 MB
/简体中文 -

终极火柴人激斗之路游戏下载 929.84 MB
/简体中文 -
射击游戏市场开卷,又冒出来一款国产射击游戏 89.22 MB
/简体中文 -
守卫雅典娜:峡谷防守生存进化官网在哪下载 最新官方下载安装地址 42.92 MB
/简体中文 -

奖励再再再升级,在魔域口袋版邂逅女神 359.14 MB
/简体中文 -
幻想大世界RPG《蓝色星原:旅谣》首次亮相Bilibili World 2024 256.96 MB
/简体中文 -
![双色球25年003期[李絮儿]推荐一码毒蓝](http://www.www.m.jnyfsp.com/uploads/images/7537710.jpg)
双色球25年003期[李絮儿]推荐一码毒蓝 31.35 MB
/简体中文 -

连送14天,魔域口袋版新服福利大放送 84.76 MB
/简体中文 -

《太空杀》联动《奥特曼》现已开启,暑期海量福利等你拿 981.61 MB
/简体中文 -

全新版本明日更新,魔域口袋版这些福利活动不容错过 82.88 MB
/简体中文 -
童心不改 来《问道》中洲欢度六一 76.31 MB
/简体中文 -

《圣斗士星矢:重生》开启618超值活动,假象者幻塔索斯登场 546.35 MB
/简体中文 -

龙珠超赛重临手游下载 677.45 MB
/简体中文 -

《模拟城市:我是市长》繁星夏梦版本全平台推出 759.58 MB
/简体中文 -

刚刚,黄圣依、杨子、麦琳、李行亮等发文 31.58 MB
/简体中文 -
2023年155期3D图谜汇总(二) 219.96 MB
/简体中文 -
疯狂布娃娃竞技手机版下载 568.36 MB
/简体中文 -

三职业大天使官方版下载 843.67 MB
/简体中文 -

全新先祖之路时装失落之潮7月4日强势袭来 127.31 MB
/简体中文 -
流星群侠传虫虫助手版下载 52.55 MB
/简体中文 -

全新激萌灵兽外观免费获得,这个夏日简直好玩又好看 12.36 MB
/简体中文 -

电糖天使降临,《和平精英》携手《百分百出品》跨界联动 36.95 MB
/简体中文 -

《魔兽世界》迪菲亚信使刷新在哪里介绍 35.94 MB
/简体中文 -
九游超凡之路手游下载 366.32 MB
/简体中文 -
果盘飞跃自我手游下载 64.72 MB
/简体中文 -
逗斗火柴人国际服最新版下载2021 97.59 MB
/简体中文 -
盛夏新篇,精彩升级《第五人格》暑期前瞻直播回顾 545.28 MB
/简体中文 -

武侠Roguelite竞技新玩法登场 九阴真经新版本今日公测 272.98 MB
/简体中文 -

财政部:2024年全国财政运行可实现收支平衡 111.51 MB
/简体中文 -

《炽焰天穹》全平台公测开启,少女们的凄美物语今日开幕 56.14 MB
/简体中文 -
长生剑派破世而来,天刀OL全新新服邀你进驻 629.65 MB
/简体中文 -
果盘暗黑联盟手游bt版下载 64.53 MB
/简体中文 -
straight hero.io游戏下载 49.62 MB
/简体中文 -
网易画加升级:打造多元化美术约稿新纪元 15.74 MB
/简体中文 -
九游剑网1归来手游下载 63.47 MB
/简体中文 -
双色球25年003期期[黑蝴蝶]本期看好一码围蓝 63.87 MB
/简体中文 -
006期天齐网解本期太湖字谜钓叟 28.25 MB
/简体中文 -

25年003期双色球吕洞宾段位诗 289.93 MB
/简体中文 -
真正做到“硬”控,这个职业原来可以如此搭配 484.13 MB
/简体中文 -
2025年006期3d图谜汇总(五) 394.65 MB
/简体中文 -

25年006期炫箫工作室所有3d字谜浅释(复制打印版) 39.55 MB
/简体中文 -

凛冬将至末日求生,《荒野迷城》S4赛季即将开启 736.53 MB
/简体中文 -
山海经之吞天妖兽最新版 651.48 MB
/简体中文 -
《英魂之刃口袋版》66节送英雄皮肤,S31赛季携免费新装等你来战 26.84 MB
/简体中文 -

《暗黑破坏神:不朽》爆金计划第五期携百万奖金来袭 27.19 MB
/简体中文 -

25006期体彩排三天齐所有字谜汇总 23.21 MB
/简体中文 -

【推荐】彩票资讯,更多中奖达人尽在宝彩网! 858.13 MB
/简体中文 -
伞舞韶华绘身入画,精美华服夏日焕新登场 44.74 MB
/简体中文 -
九游飞跃自我手游下载 92.39 MB
/简体中文 -

决胜劳塔罗初临赛场,与他并肩作战一同探寻答案 19.45 MB
/简体中文 -
暗潮涌动,《暗黑破坏神:不朽》四大全新魔神来袭 62.88 MB
/简体中文 -

神秘新门派惊现江湖,《剑侠世界:起源》即将迎来大动作 393.21 MB
/简体中文 -

《和平精英》首套高定礼服“梦海之灵”神装浪漫发布 98.32 MB
/简体中文 -

九游复古无双手游下载 97.37 MB
/简体中文 -

全服唯一永久坐骑首曝,音乐节今日开票 36.61 MB
/简体中文 -
何时入坑都不晚,魔域口袋版新手福利一览 94.94 MB
/简体中文 -

《模拟城市:我是市长》感恩相伴主题建筑抢先看 99.31 MB
/简体中文 -

异兽大冒险公益服下载 923.23 MB
/简体中文 -

25年006期齐齐哈尔市本期3D北京谜语 984.89 MB
/简体中文 -
006期天齐网解本期太湖字谜钓叟 722.16 MB
/简体中文 -
最小成本培养换取极致收益,《天下》手游元魂珠培养攻略来袭 993.72 MB
/简体中文 -
《排球少年:新的征程》手游预约开启 飞吧,冲向新的顶端 81.28 MB
/简体中文 -
2025年006期[莱斯特]排列三和值谜 28.27 MB
/简体中文 -

《球球大作战》历史第1款光环返场,飞火流炎6.1登录送 21.39 MB
/简体中文 -
2024“打虎”超50名!反腐败持续高压力度不减 352.43 MB
/简体中文 -
全新版本明日更新,魔域口袋版这些福利活动不容错过 693.15 MB
/简体中文 -
《模拟城市:我是市长》繁星夏梦版本全平台推出 94.52 MB
/简体中文 -

25006期福彩3D麦久免费综合预测汇总(天齐网独家整理) 36.25 MB
/简体中文 -

漫威全家桶登陆BW, 死侍玩《漫威终极逆转》引爆现场 91.97 MB
/简体中文 -

预约领多重福利,魔域口袋版年中版本预约开启 362.23 MB
/简体中文 -

我是超级英雄游戏下载手机版 71.65 MB
/简体中文 -
《时空中的绘旅人》罗夏生日活动正午时幻光8月1日开启 571.48 MB
/简体中文 -

和平精英与巴啦啦小魔仙联动亮相,刘美含开启华丽全身变 848.52 MB
/简体中文 -
《暗黑破坏神:不朽》爆金计划第五期携百万奖金来袭 25.76 MB
/简体中文 -
straight hero.io游戏下载 743.41 MB
/简体中文 -

潜鳞逐浪,纵海探珠《阴阳师》骁浪荒川之主新皮肤即将上线 22.81 MB
/简体中文 -
小军图25006期赢钱快报天玄报 298.99 MB
/简体中文 -
《英魂之刃口袋版》66节福利狂欢 西门飞雪限定国风皮肤亮相 51.87 MB
/简体中文 -

兄弟来战,天龙八部手游雄霸天下大赛报名即将开启 355.84 MB
/简体中文 -
现在还有夺金点,魔域口袋版火热夺魁中 85.98 MB
/简体中文 -
趣玩成语官网在哪下载 最新官方下载安装地址 584.67 MB
/简体中文 -

悬天神木隐见应龙之影,《天下》手游全新团本来战 97.46 MB
/简体中文 -

双色球25003期老田基本号码推荐 973.69 MB
/简体中文 -
23155期真黑圣手3D今日字谜 363.23 MB
/简体中文 -

放置奇迹王者正版下载 791.75 MB
/简体中文 -
真正做到“硬”控,这个职业原来可以如此搭配 96.27 MB
/简体中文 -

假面骑士city wars游戏下载 477.64 MB
/简体中文 -

《西游:笔绘西行》1.1新版本焚扇劫心主题活动前瞻 956.35 MB
/简体中文 -
网易Y3高校赛夏令营开启,拿到offer的大学生们要搞事情啦 65.94 MB
/简体中文 -

《模拟城市:我是市长》缤纷绚丽主题建筑抢先看 972.35 MB
/简体中文 -
终焉誓约国际服游戏下载 919.58 MB
/简体中文 -

赛博都市2040手游下载 63.66 MB
/简体中文 -

网易新作《七日世界》让老外们集体“真香”了 73.28 MB
/简体中文 -

《模拟城市:我是市长》建设港口为城市打造如画美景 979.27 MB
/简体中文 -

《暗黑破坏神:不朽》联动美团神券节星聚场火爆开启 46.12 MB
/简体中文 -

蛋蛋小子大闯关游戏下载 588.72 MB
/简体中文 -
一次就能体验人生四大喜,长安穿越指南第三期来啦 643.34 MB
/简体中文 -
捉鬼事务所官网在哪下载 最新官方下载安装地址 996.64 MB
/简体中文 -
四大天王合体开唱?刘德华表态了 524.14 MB
/简体中文 -

《方舟生存飞升》全新社交玩法方舟俱乐部开启 77.49 MB
/简体中文 -
《天下》手游8周年资料片庆今朝7月31日狂欢来袭 734.85 MB
/简体中文 -
双色球25003期图迷画迷汇总(天齐整理) 792.61 MB
/简体中文 -
《模拟城市:我是市长》繁星夏梦版本全平台推出 56.43 MB
/简体中文 -
行舟启航庆端午,《战舰世界》主题任务现已开启 449.27 MB
/简体中文 -
《模拟城市:我是市长》激情盛夏版本登陆苹果AppStore 253.38 MB
/简体中文 -

晚秋图25006期3d晚秋和值迷图谜版 576.65 MB
/简体中文 -
童心不改 来《问道》中洲欢度六一 38.47 MB
/简体中文 -
《西游:笔绘西行》出场角色牛魔王公布 847.56 MB
/简体中文 -
“智慧成长,安全先行”边锋网络携手各界共同引领青春航道 56.33 MB
/简体中文 -
复古至尊合击手游下载 796.24 MB
/简体中文 -
双色球068期公益时报一语定蓝字谜 192.97 MB
/简体中文 -
【推荐】宝彩专家优质文章推荐,精准分析助力大奖! 48.55 MB
/简体中文 -
25年006期3D专家解今日太湖字谜汇总(天齐网整理汇总) 79.39 MB
/简体中文 -
25年006期3d试机号后黑圣手一语定号 73.31 MB
/简体中文 -
《排球少年:新的征程》手游预约开启 飞吧,冲向新的顶端 123.37 MB
/简体中文 -
缝都可以缝好玩吗 缝都可以缝玩法简介 83.58 MB
/简体中文 -
机器人建筑大师手机版下载 311.16 MB
/简体中文 -

枣庄红人25年003期杀双色球蓝球图迷 916.31 MB
/简体中文 -

《梦幻西游三维版》全新传说级召唤兽应龙霸气登场 76.99 MB
/简体中文 -

第五人格×三丽鸥大明星联动第二弹开启 329.62 MB
/简体中文 -
一次就能体验人生四大喜,长安穿越指南第三期来啦 359.34 MB
/简体中文 -

25年006期小糊涂+老糊涂+侠客3D字谜 13.94 MB
/简体中文 -
预约《剑侠世界端游》新服送百万绑金,领白秋琳同伴 18.57 MB
/简体中文 -
《英魂之刃口袋版》66节狂欢庆典:英雄及皮肤大放送 654.35 MB
/简体中文 -
《射雕》全真轻剑高伤害搭配介绍 射雕攻略详解 274.74 MB
/简体中文 -

职业真的平衡了,魔域口袋版全新星辰之力系统上线 448.21 MB
/简体中文 -
大的要来了,魔域口袋版年中全职业加强 476.45 MB
/简体中文 -
2024“打虎”超50名!反腐败持续高压力度不减 215.73 MB
/简体中文 -

古墓登场,剑指铁浮城《剑侠世界:起源》新资料片震撼公布 145.65 MB
/简体中文 -
goddess魔剑契约手机版下载 67.38 MB
/简体中文 -
喧嚣再起,《第五人格》2024IVL夏季赛6月8日正式开赛 298.35 MB
/简体中文 -
《永劫无间》定胜终测开启,首发游戏Copilot智能AI队友功能 32.61 MB
/简体中文 -

25年006期福彩3d试机号后首奖诗 15.94 MB
/简体中文 -

符文加成,《暗黑破坏神:不朽》符文系统开启备战 95.65 MB
/简体中文 -

KK官方对战平台存档翻倍活动劲爆开启 663.85 MB
/简体中文 -

《闪耀暖暖》主题活动“鲸落忆海 浩瀚生花”开启 83.52 MB
/简体中文 -
25年008期双色球红谷子玄机诗谜 25.59 MB
/简体中文 -

故宫北院区核心建筑主体结构封顶 87.66 MB
/简体中文 -
25年006期炫箫工作室所有3d字谜浅释(复制打印版) 49.37 MB
/简体中文 -
![[天齐东塔]23155期3D专家预测今日杀码:7](http://www.www.m.jnyfsp.com/uploads/images/2680590.jpg)
[天齐东塔]23155期3D专家预测今日杀码:7 946.91 MB
/简体中文 -

《大话西游》22周年玩家情义片上线,代言人大鹏演绎兄弟情义 274.83 MB
/简体中文 -

25006期狂想P3本期字谜 162.25 MB
/简体中文 -

英雄这边请h5在线玩下载 83.51 MB
/简体中文 -

《侠客风云传OL》盛夏狂欢,顶级侠客集结令 73.97 MB
/简体中文 -

赛季中期“长安内城”正式上线,奢华坐骑九尾天狐上线即领 52.73 MB
/简体中文 -
和平精英与巴啦啦小魔仙联动亮相,刘美含开启华丽全身变 38.54 MB
/简体中文 -

《天下》手游少侠联动荒野行动开展衣橱共享计划 49.17 MB
/简体中文 -
《暗黑破坏神:不朽》联动美团神券节星聚场火爆开启 795.32 MB
/简体中文 -

福彩3d23155期白面书生杀码字谜 562.18 MB
/简体中文 -

25006期福彩3D开机号分析 12.56 MB
/简体中文 -

比剪刀石头布还刺激,《漫威终极逆转》共用回合制解析 815.86 MB
/简体中文 -
真人互动影像“游戏”,《失业了,我获得了亿万游戏财产!》值得细品 885.27 MB
/简体中文 -
超级龙珠战士游戏下载 76.47 MB
/简体中文 -

央视《西游记》时隔25年重拍,网易耗资百亿搭建东海龙宫 781.19 MB
/简体中文 -
《月圆之夜》S4团建第二战来袭,看主播再度对决 586.61 MB
/简体中文 -
双色球25003期朋哥本期红球综合预测 982.42 MB
/简体中文 -

《放开那三国3》流焰陆逊 酣战沙场 714.29 MB
/简体中文 -

玩彩人25年003期双色球杀三蓝图谜 515.89 MB
/简体中文 -
李斯特菌的传说手游下载 497.83 MB
/简体中文 -
组队打金一局暴富,《球球大作战》猎魔新玩法今日上线 13.98 MB
/简体中文 -

口袋玩家生存之战游戏下载 766.66 MB
/简体中文 -

23年155期一品公子3d天机诗 968.99 MB
/简体中文 -
好活当赏国产疯狂动物城版战地,老外狂喜 895.39 MB
/简体中文 -

双色球23068期牛彩字谜诗迷汇总(天齐整理) 517.31 MB
/简体中文 -
电糖天使降临,《和平精英》携手《百分百出品》跨界联动 61.27 MB
/简体中文 -

《剑侠世界端游》年中资料片“与君相伴”今日上线,真情回馈 453.36 MB
/简体中文 -
九游超凡之路手游下载 22.82 MB
/简体中文 -

【方块方舟】欢乐像素世界,童趣无限,儿童节版本开启 479.66 MB
/简体中文 -
单机联网成功破壁,《燕云十六声》是如何实现“既要又要”的 974.14 MB
/简体中文 -

九霄缳神记中文版下载 24.91 MB
/简体中文 -
2025年006期3D图谜汇总(九) 28.84 MB
/简体中文 -
前哨直播精彩不断《FGO》8周年庆典活动即将盛大开幕 42.33 MB
/简体中文 -
历史上的今天双色球1月7日开奖号码汇总 718.53 MB
/简体中文 -

中西方天神齐降临 《山海剑途》特色玩法曝光 36.21 MB
/简体中文 -
全新花魁赛曝光,魔域口袋版年度玩家盛典即将上线 553.42 MB
/简体中文 -

天刀OL阳光沙滩攻略,解密夏天解暑的正确打开方式 35.31 MB
/简体中文 -

23年155期小新解3d太湖四句玄机诗 54.54 MB
/简体中文 -

争做顶级收藏家 ,《战舰世界》迎来大量宝藏 896.54 MB
/简体中文 -
25006期狂想P3本期字谜 26.18 MB
/简体中文 -

《方舟生存飞升》新生物恐鳄上线,中心岛地图将开启跨服转移 597.61 MB
/简体中文 -

这游戏这么多美女,魔域口袋版花魁赛送豪礼 472.37 MB
/简体中文 -
BOE(京东方)携手电竞高阶联盟合作伙伴亮相ChinaJoy 846.53 MB
/简体中文 -

“暖”从何而来?记者走访看羽绒服“科技范” 677.41 MB
/简体中文 -
《魔力宝贝:复兴》6月19日公测开启,刘亦菲闪耀品牌片引领新纪元 843.87 MB
/简体中文 -
25年006期福彩詹天佑3D点评分析 645.49 MB
/简体中文 -
体彩p32023年155期牛彩今日字谜汇总 47.78 MB
/简体中文 -

23年155期蝶中蝶解太湖一门人 83.39 MB
/简体中文 -

超级英雄毒液手游下载 59.45 MB
/简体中文 -
点灯人手机版官方下载 32.81 MB
/简体中文 -

送皮肤送英雄,《英魂之刃口袋版》66节清凉泳装登场 381.92 MB
/简体中文 -
植物球吃僵尸,《球球大作战》联动《植物大战僵尸2》开启 975.95 MB
/简体中文 -
白熊猫25年003期双色球杀两枚红球图谜 96.96 MB
/简体中文 -

“船”新玩法 《剑网一》资料片踏浪覆海今日上线 88.51 MB
/简体中文 -
上市两年市值低估的蜗牛游戏披露多款新品,未来预期持续向好 33.23 MB
/简体中文 -

英思特:公司产品可应用于搭载人工智能、AI的消费电子、智能家居等相关终端产品 89.81 MB
/简体中文 -

六一更新,《太空杀》免费套装与幸存者双人模式同步上线 137.71 MB
/简体中文 -
![排三25006期[装饰城]定胆字谜](http://www.www.m.jnyfsp.com/uploads/images/2940190.jpg)
排三25006期[装饰城]定胆字谜 84.23 MB
/简体中文 -

双色球23068期 朋哥今期蓝球综合分析 184.73 MB
/简体中文 -

百趣荣耀沙城安卓下载 85.36 MB
/简体中文 -
连送14天,魔域口袋版新服福利大放送 79.61 MB
/简体中文 -
争做顶级收藏家 ,《战舰世界》迎来大量宝藏 81.12 MB
/简体中文 -
25年008期双色球红谷子玄机诗谜 24.38 MB
/简体中文 -

九游修仙绘卷手游下载 456.78 MB
/简体中文 -
最小成本培养换取极致收益,《天下》手游元魂珠培养攻略来袭 636.15 MB
/简体中文 -

《问道》电脑版全新十阶坐骑天机武威联动紫禁城,引领文创潮流 798.69 MB
/简体中文 -

巨兽战场手游3k版下载 79.79 MB
/简体中文 -

《无期迷途》「沉溺无忧海」夏日限时活动今日开启 42.74 MB
/简体中文 -

25年006期黑胆王福彩3d试机后推荐 91.31 MB
/简体中文 -
重振旗鼓,MRCXC歌剧演员华丽蜕变四抓终结比赛 791.28 MB
/简体中文 -

这游戏真有女玩家,魔域口袋版花魁赛进行中 451.79 MB
/简体中文 -
点灯人手机版官方下载 73.25 MB
/简体中文 -

《闪耀暖暖》活动“银河舞厅之夜”上线, “熔炼真知”活动同步开启 712.53 MB
/简体中文 -
《圣斗士星矢:重生》开启618超值活动,假象者幻塔索斯登场 888.76 MB
/简体中文 -
保送新手14天,魔域口袋版新手攻略一篇看懂 761.63 MB
/简体中文 -

“纸”绘长安繁华,大唐无双手游×洁云联动开启 25.18 MB
/简体中文 -
元气骑士oppo版下载 48.45 MB
/简体中文 -

《新大话西游3》新服新万象,专属守护培养新锐副本等你体验 211.41 MB
/简体中文 -

2024狼人杀英雄联赛来袭,升级亮点大揭秘 84.53 MB
/简体中文 -

荒野迷城官宣游戏代言人,东方拳王张志磊降临荒野 54.28 MB
/简体中文 -

火柴蜘蛛侠英雄2城市孤胆车神下载 383.84 MB
/简体中文 -

火柴人功夫之王手机版下载 71.57 MB
/简体中文 -
《英魂之刃口袋版》66节福利狂欢 西门飞雪限定国风皮肤亮相 724.34 MB
/简体中文 -

玄溟为什么这样设计,一切要从十年前说起 31.23 MB
/简体中文 -
《问道》经典版新服“二〇二四”正式定档,抢注活动现已开启 31.65 MB
/简体中文 -

无双战车坦克射击下载 622.81 MB
/简体中文 -

机器组装决斗中文版下载 463.23 MB
/简体中文 -
中龙图25006期福寿禄八卦图三意图迷 74.82 MB
/简体中文 -
超能英雄钢铁手游下载 868.57 MB
/简体中文 -
出奇制胜,《第五人格》2024IVL夏季赛第一周赛报发布 84.21 MB
/简体中文 -

龙珠超英雄手机版下载 262.76 MB
/简体中文 -

永劫无间手游公测定档7月25日, 开启动作竞技新篇章 413.52 MB
/简体中文 -

大话西游时光巡礼太原站圆满落幕,下一站上海等你来! 29.81 MB
/简体中文 -
《闪耀暖暖》活动“银河舞厅之夜”上线, “熔炼真知”活动同步开启 298.23 MB
/简体中文 -
火柴人功夫之王手机版下载 451.58 MB
/简体中文 -

九游造梦大乱斗手游下载 66.73 MB
/简体中文 -

25006期一品公子P3天机诗 226.48 MB
/简体中文 -
25年006期神舟图谜画迷汇总(天齐采摘) 41.59 MB
/简体中文 -

双色球2025年003期名家精选号码推荐总汇 27.64 MB
/简体中文 -
双色球25003期图迷画迷汇总(天齐整理) 367.96 MB
/简体中文 -
财政部:2024年全国财政运行可实现收支平衡 86.84 MB
/简体中文 -
双色球25年003期[李絮儿]推荐一码毒蓝 66.38 MB
/简体中文 -

《剑侠世界端游》绿色版资料片今日上线 69.36 MB
/简体中文 -
神仙联动 童趣来袭 《剑网3缘起》×《非人哉》邀你一起过六一 763.89 MB
/简体中文 -

25年006期金刚破p3藏机诗 464.83 MB
/简体中文 -

元素契约官方游戏下载 766.83 MB
/简体中文 -

钢铁英雄战场官方版下载 17.89 MB
/简体中文 -
体彩p32025年006期[乾坤]一句定三码 824.16 MB
/简体中文 -
《闪耀暖暖》活动“银河舞厅之夜”上线, “熔炼真知”活动同步开启 83.66 MB
/简体中文 -

航海王热血航线公益服下载 76.46 MB
/简体中文 -

新门派玄机,《剑侠世界3》资料片“玄机千变”今日上线 833.36 MB
/简体中文 -
天下CJ WORK,2024年Chinajoy大荒乐园等你来探秘 75.45 MB
/简体中文 -
![体彩p325006期[勇往直前]定胆谜](http://www.www.m.jnyfsp.com/uploads/images/6439910.jpg)
体彩p325006期[勇往直前]定胆谜 831.97 MB
/简体中文 -

《西游:笔绘西行》出场角色九头鸟震撼发布 127.63 MB
/简体中文 -

夏日新品,《剑侠世界3》新坐骑新宠物霸气登场 78.59 MB
/简体中文 -

2025年003期双色球专家预测分析汇总(天齐网整理发布) 19.54 MB
/简体中文 -

燕云十六声亮相PS发布会,打入国产3A赛道 181.28 MB
/简体中文 -

双色球25年003期鬼谷子本期具体条件推荐 65.57 MB
/简体中文 -
增能菲戈首登绿茵,右路天尊传中大师降临 68.96 MB
/简体中文 -

《射雕》山茱萸获取攻略 射雕攻略推荐 518.72 MB
/简体中文 -

《时空中的绘旅人》全新琴宁岛天气系统6月27日上线 831.43 MB
/简体中文 -

无敌士兵英雄对战下载游戏 836.37 MB
/简体中文 -

生存大战大逃杀最新版下载 13.68 MB
/简体中文 -

技能强化,《问道》神通念头怎么用 95.32 MB
/简体中文 -
23155期真黑圣手3D今日字谜 166.14 MB
/简体中文 -
《剑网3无界》预下载正式开启 一起相约无界江湖 375.45 MB
/简体中文 -

火柴人归来华为版下载 929.82 MB
/简体中文 -
点灯人手机版官方下载 173.79 MB
/简体中文 -
连送14天,魔域口袋版新服福利大放送 55.24 MB
/简体中文 -

ARK系列发行商蜗牛游戏发布3A开放宇宙游戏 544.54 MB
/简体中文 -
2025年006期3D图谜汇总(二) 969.39 MB
/简体中文 -
夏日新品,《剑侠世界3》新坐骑新宠物霸气登场 539.54 MB
/简体中文 -
《远征OL》联动《饿了么》今日开启美食节新区饕餮 454.93 MB
/简体中文 -

烈火传奇手游官方下载 35.23 MB
/简体中文 -
23年155期小新解3d太湖四句玄机诗 821.16 MB
/简体中文 -
单机联网成功破壁,《燕云十六声》是如何实现“既要又要”的 28.84 MB
/简体中文 -
《模拟城市:我是市长》明珠璀璨限时活动抢先看 47.42 MB
/简体中文 -
《西游:笔绘西行》出场角色九头鸟震撼发布 887.63 MB
/简体中文 -
2023年155期3d图迷汇总(六) 64.86 MB
/简体中文 -
全新激萌灵兽外观免费获得,这个夏日简直好玩又好看 313.29 MB
/简体中文 -

《圣斗士星矢:重生2》定档8月21日全平台公测 29.31 MB
/简体中文 -

将军不败情定三生手游下载 87.93 MB
/简体中文 -

《英魂之刃口袋版》2024HELM夏季赛线下赛玩家观赛报名开启 63.85 MB
/简体中文 -

大天使合击版手游下载 457.58 MB
/简体中文 -
故宫北院区核心建筑主体结构封顶 988.94 MB
/简体中文 -

第一召唤师中文版手游下载 639.99 MB
/简体中文 -
果盘武功来了手游下载 566.72 MB
/简体中文 -

翻滚吧筋斗云华为版下载 11.71 MB
/简体中文 -
真人互动影像“游戏”,《失业了,我获得了亿万游戏财产!》值得细品 84.33 MB
/简体中文 -
独占鳌头,MRC战队势头强劲领跑积分榜 449.11 MB
/简体中文 -
《射雕》山茱萸获取攻略 射雕攻略推荐 982.77 MB
/简体中文 -

豆豆猫淘汰赛游戏下载 62.92 MB
/简体中文 -

25年006期孔方来萃专解太湖钓叟三字诀 719.98 MB
/简体中文 -

23155期体彩排三天齐所有字谜汇总 67.22 MB
/简体中文 -

2023年155期千万大奖一语定三胆 624.91 MB
/简体中文 -

《葫芦娃2》评论送福利活动,假如葫芦娃参加奥运会 926.95 MB
/简体中文 -
英雄这边请h5在线玩下载 28.86 MB
/简体中文 -

互殴群侠传破解版下载 595.19 MB
/简体中文 -
新手必看,魔域口袋版最速新人上手攻略 762.27 MB
/简体中文 -
双色球25003期朋哥本期红球综合预测 196.71 MB
/简体中文 -
《远征OL》联动《饿了么》今日开启美食节新区饕餮 753.71 MB
/简体中文 -
普通的狗哥模拟器游戏下载 84.32 MB
/简体中文 -
赛季中期“长安内城”正式上线,奢华坐骑九尾天狐上线即领 91.51 MB
/简体中文 -
九游奇幻祖玛手游下载 798.48 MB
/简体中文 -

福彩3D155期扶风唤雨歇后语 29.63 MB
/简体中文 -
![福彩3D2025年006期[周义宾]解太湖谜语一碗汤](http://www.www.m.jnyfsp.com/uploads/images/4472550.jpg)
福彩3D2025年006期[周义宾]解太湖谜语一碗汤 99.49 MB
/简体中文 -

年中专属新服活动,魔域口袋版想入坑就看这篇 23.26 MB
/简体中文 -

自由探索乐无边 九阴真经8月资料片漠西特色玩法首曝 631.23 MB
/简体中文 -
起源之战复仇官方下载 293.56 MB
/简体中文 -
![双色球25年003期[麦丽素]今日012路尾分析](http://www.www.m.jnyfsp.com/uploads/images/4837140.jpg)
双色球25年003期[麦丽素]今日012路尾分析 978.31 MB
/简体中文 -
无限刷怪 《山海剑途》超炫技能暴爽体验 86.86 MB
/简体中文 -
《问道》电脑版7月破阵探宝活动全版本开启 88.45 MB
/简体中文 -
《崩坏星穹铁道》记忆开拓者养成攻略 记忆开拓者怎么培养 425.24 MB
/简体中文 -
崩坏星穹铁道3.1版本新角色是谁呢 新版本角色介绍 546.53 MB
/简体中文 -

心跳之约,《第五人格》心跳·游园会嘉年华线下活动回顾 569.31 MB
/简体中文 -
重回三族版本,免费版怀旧服815开启 63.83 MB
/简体中文 -
职业真的平衡了,魔域口袋版全新星辰之力系统上线 31.13 MB
/简体中文 -

吸血传奇红包手游下载 894.47 MB
/简体中文 -
《蛋仔派对》全新刺激追逃玩法“逃出惊魂夜”恐怖来袭 33.18 MB
/简体中文 -

毛毛大团建,最亮眼的竟是这款射击游戏 95.71 MB
/简体中文 -

荣耀军团满vip果盘版下载 489.95 MB
/简体中文 -
25年003期天齐网今晚双色球图谜总汇 17.25 MB
/简体中文 -
2025006期齐齐哈尔市当期P3北京谜语 24.45 MB
/简体中文 -
全新花魁赛曝光,魔域口袋版年度玩家盛典即将上线 49.49 MB
/简体中文 -
双色球25年003期[麦丽素]今日012路尾分析 245.93 MB
/简体中文 -

《模拟城市:我是市长》花城新喜限时活动精彩曝光 93.95 MB
/简体中文 -
《崩坏星穹铁道》记忆开拓者养成攻略 记忆开拓者怎么培养 72.29 MB
/简体中文 -
铁浮城主虚位以待,《剑侠世界:起源》新帮战等你成就霸业 26.45 MB
/简体中文 -

《英魂之刃口袋版》携手《少年歌行》,与你共赴武侠奇缘 88.74 MB
/简体中文 -

《问道》与《紫禁城》合作打造全新坐骑,尽显华夏魅力 736.14 MB
/简体中文 -
掠夺之剑暗影大陆中文版下载 58.39 MB
/简体中文 -
下一代竞技卡牌手游《漫威终极逆转》登陆App store 639.42 MB
/简体中文 -

《燕云十六声》浴袍黄金缕获取办法 99.14 MB
/简体中文 -

《模拟城市:我是市长》将迎来蟾桂映秋版本 297.96 MB
/简体中文 -
连送14天,魔域口袋版新服福利大放送 912.25 MB
/简体中文 -

《圣斗士星矢:重生2》手游CG《重塑》发布,公测倒计时7天 992.74 MB
/简体中文 -

少年封印师桔梗手游下载 84.23 MB
/简体中文 -

25006期3D丹东解太湖 天龙一语 布衣神算 56.54 MB
/简体中文 -

双色球23068期段王爷段位字谜 371.57 MB
/简体中文 -
2025年006期3d图谜汇总(五) 749.79 MB
/简体中文 -
双色球25年003期天吉龙头凤尾鸟语断蓝图 883.39 MB
/简体中文 -

暗黑之林大天使手游下载 93.78 MB
/简体中文 -

《放开那三国2》典藏武将携新时装今日上新 842.38 MB
/简体中文 -
2025006期3D唐龙点评+唐龙一胆 584.11 MB
/简体中文 -
极限博弈,FPX.ZQ求生者无瑕配合逆境三出 933.42 MB
/简体中文 -

玩转武林,《剑侠世界:起源》28条门派路线任选 82.34 MB
/简体中文 -
dawnblade中文版下载 624.21 MB
/简体中文 -

死侍上场终极逆转,《漫威终极逆转》Chinajoy回顾 595.32 MB
/简体中文 -

双色球第23068期怪老人红球段位字谜 37.87 MB
/简体中文 -

仓鼠pvp争取自由游戏下载 636.64 MB
/简体中文 -
![排三25006期[静怜姬]定胆字谜](http://www.www.m.jnyfsp.com/uploads/images/9970820.jpg)
排三25006期[静怜姬]定胆字谜 819.38 MB
/简体中文 -
2025年006期[莱斯特]排列三和值谜 57.35 MB
/简体中文 -
最后的原始人九游版下载 718.85 MB
/简体中文 -
《模拟城市:我是市长》繁星夏梦版本登陆苹果AppStore 569.37 MB
/简体中文 -
兄弟来战,天龙八部手游雄霸天下大赛报名即将开启 12.88 MB
/简体中文 -
互殴群侠传破解版下载 383.57 MB
/简体中文 -
Steam首届Furry游戏节,这款国产射击游戏脱颖而出 326.33 MB
/简体中文 -
2025年006期牛彩所有原创图谜 44.11 MB
/简体中文 -
天刀OL阳光沙滩攻略,解密夏天解暑的正确打开方式 773.36 MB
/简体中文 -
二周年庆狂撒百万福利,S9赛季今日更新 959.95 MB
/简体中文 -
烈火锻萃《第五人格》第三十三赛季精华3爆料来袭 686.83 MB
/简体中文 -

25年006期正老北京本期3D字谜 139.83 MB
/简体中文 -
极限博弈,FPX.ZQ求生者无瑕配合逆境三出 671.44 MB
/简体中文 -

今年155期福彩3d所有字谜汇总 448.33 MB
/简体中文 -
《圣斗士星矢:重生2》斗士档案人气圣斗士公布(第一期) 14.31 MB
/简体中文 -

跨服较量,《剑侠世界:起源》手游上演强强交锋 164.64 MB
/简体中文 -

西山居姚喆:以精品游戏彰显中国力量,打造全球影响力电竞产品 988.56 MB
/简体中文 -

《方块方舟》冰魔蝎登场开启夏日狂欢,Steam夏季史低促销 22.27 MB
/简体中文 -
“纸”绘长安繁华,大唐无双手游×洁云联动开启 91.97 MB
/简体中文 -
双色球25年003期天吉龙头凤尾鸟语断蓝图 74.79 MB
/简体中文 -

坦克吃鸡大战游戏下载 38.58 MB
/简体中文 -

火热对决,《巅峰坦克》2024星路联赛年中总决赛7.27开启 212.57 MB
/简体中文 -
伞舞韶华绘身入画,精美华服夏日焕新登场 34.98 MB
/简体中文 -

一剑永恒之纵剑天下游戏下载 42.24 MB
/简体中文 -
双色球23068期脑筋急转弯定龙头字谜 96.71 MB
/简体中文 -
全新匠石系统怎么玩,魔域口袋版助你无痛涨输出 455.82 MB
/简体中文 -

25003期双色球专家工作室预测推荐总汇 171.14 MB
/简体中文 -

《蛋仔派对》电影节嘉宾惊喜亮相,瓶盖外观喜迎上新 346.61 MB
/简体中文 -

体彩排三23第155期牛彩字谜汇总(天齐网独家整理) 932.49 MB
/简体中文 -

刀刀爆红包传奇游戏下载 231.79 MB
/简体中文 -

3D字总汇 25006期所有字谜汇总 42.76 MB
/简体中文 -

《方舟:生存飞升》免费DLC“中心岛”上线,生物“炽炎猫”登场 582.97 MB
/简体中文 -

创世封神之王城战歌游戏 118.36 MB
/简体中文 -
25年006期神舟图谜画迷汇总(天齐采摘) 325.83 MB
/简体中文 -
25年006期正老北京本期3D字谜 548.27 MB
/简体中文 -

战斧疾驰dash官方版下载 511.19 MB
/简体中文 -
烈火传奇手游官方下载 996.81 MB
/简体中文 -

二载同行,共赴狂欢《蛋仔派对》2周年庆典直播爆料汇总 262.64 MB
/简体中文 -
玄机千变,《剑侠世界3》新版本新玩法攻略公布 996.88 MB
/简体中文 -

终极维京人手机版下载 94.53 MB
/简体中文 -
最新年兽直接送,魔域口袋版新服福利不容错过 153.99 MB
/简体中文 -

妖怪冒险计划游戏下载 17.23 MB
/简体中文 -
一剑永恒之纵剑天下游戏下载 48.76 MB
/简体中文 -
轻松冒险不伤肝,《九畿:岐风之旅》辰极纪测试今日开启 291.93 MB
/简体中文 -
《问道》电脑版全新十阶坐骑天机武威联动紫禁城,引领文创潮流 448.57 MB
/简体中文 -

无尽天命安卓手机版下载 971.74 MB
/简体中文 -

九阳神功起源手游下载 544.77 MB
/简体中文 -
![2025年006期[方舟]排列三杀码字谜](http://www.www.m.jnyfsp.com/uploads/images/5525280.jpg)
2025年006期[方舟]排列三杀码字谜 123.37 MB
/简体中文 -

以守护之名 ,《战舰世界》联动大力水手开启 554.81 MB
/简体中文 -
25年008期双色球红谷子玄机诗谜 28.76 MB
/简体中文 -
《英魂之刃口袋版》精英联赛精彩时刻 赵云白马银枪大招一控四 686.13 MB
/简体中文 -
25年006期炫箫工作室所有3d字谜浅释(复制打印版) 662.65 MB
/简体中文 -
155期天齐藏机四字定胆 19.99 MB
/简体中文 -

漫威超级争霸战虫虫助手版下载 784.22 MB
/简体中文 -
23年155期小新解3d太湖四句玄机诗 788.99 MB
/简体中文 -

2023155期天齐大哥和值迷 818.94 MB
/简体中文 -

12小时百万曝光,挑战网易直播记录 16.99 MB
/简体中文 -
心跳之约,《第五人格》心跳·游园会嘉年华线下活动回顾 445.19 MB
/简体中文 -

天赐之福降临 《坦克世界》2024周年庆预告片发布 655.59 MB
/简体中文 -

战天传奇4399版下载 81.76 MB
/简体中文 -
少年封印师桔梗手游下载 156.52 MB
/简体中文 -
小小虎25006期炎黄子孙小小虎图迷 87.16 MB
/简体中文 -
《剑侠世界:起源》“古墓剑影”资料片6.20上线 46.75 MB
/简体中文 -
《模拟城市:我是市长》繁星夏梦版本登陆苹果AppStore 86.88 MB
/简体中文 -
赛季中期“长安内城”正式上线,奢华坐骑九尾天狐上线即领 415.97 MB
/简体中文 -
《模拟城市:我是市长》繁星夏梦版本登陆苹果AppStore 892.29 MB
/简体中文 -

太空格斗模拟器最新版下载 117.18 MB
/简体中文 -
2025006期齐齐哈尔市当期P3北京谜语 162.47 MB
/简体中文 -
燃烧吧航海王满v公益服下载 78.62 MB
/简体中文 -

嗨翻炎炎夏日 《剑网2》新传版今日开启暑期嘉年华 53.79 MB
/简体中文 -

崩坏星穹铁道卡芙卡什么时候出 崩坏星穹铁道卡芙卡上线时间介绍 94.46 MB
/简体中文 -
假面骑士city wars游戏下载 775.98 MB
/简体中文 -
2025年006期牛彩所有原创图谜 939.21 MB
/简体中文 -
《剑网3无界》预下载正式开启 一起相约无界江湖 899.93 MB
/简体中文 -
《问道》时间版年度大服“甲辰”特色改版之玩法与活动 163.81 MB
/简体中文 -
玩转武林,《剑侠世界:起源》28条门派路线任选 299.86 MB
/简体中文 -
《英魂之刃口袋版》66节福利大狂欢,英雄与皮肤豪气送 63.81 MB
/简体中文 -

广州龙狮辟谣队员行李箱装女友进宿舍:不实消息 829.71 MB
/简体中文 -

25006期福彩3d试机号后预测汇总(彩友版) 528.33 MB
/简体中文 -
大话西游时光巡礼太原站圆满落幕,下一站上海等你来! 39.82 MB
/简体中文 -

上阵父子兵,《坦克世界》父亲节线下观影圆满落幕 881.61 MB
/简体中文 -
轻松冒险不伤肝,《九畿:岐风之旅》辰极纪测试今日开启 38.19 MB
/简体中文 -
跨服较量,《剑侠世界:起源》手游上演强强交锋 215.23 MB
/简体中文 -
果盘霸气英雄送gm1版下载 24.73 MB
/简体中文 -
超级英雄毒液手游下载 672.44 MB
/简体中文 -
《放开那三国3》流焰陆逊 酣战沙场 65.23 MB
/简体中文 -

25年006期本期体彩P3正版藏机诗汇总 864.24 MB
/简体中文 -
25003期双色球专家工作室预测推荐总汇 941.99 MB
/简体中文 -
25006期福彩3d试机号后预测汇总(彩友版) 67.55 MB
/简体中文 -

倾听万物之声《第五人格》盲女限时稀世时装礼包上线 94.81 MB
/简体中文 -
2025006期全部3d藏机图汇总 193.44 MB
/简体中文 -
创世封神之王城战歌游戏 322.21 MB
/简体中文 -
2025年006期3D图谜汇总(九) 54.85 MB
/简体中文 -

末日重生天启手游下载 55.95 MB
/简体中文 -
仙山百宝现,《问道》电脑版百宝翻牌活动限时开启 43.93 MB
/简体中文 -
生存大战大逃杀最新版下载 534.14 MB
/简体中文 -

御剑诀之仙缘游戏下载 689.41 MB
/简体中文 -

25年003期双色球羽旋公益诗谜 61.31 MB
/简体中文 -
2023年155期3D图迷汇总(四) 31.87 MB
/简体中文 -
尽情发挥新奇创意,全新染色系统即将上线 462.37 MB
/简体中文 -

《模拟城市:我是市长》新月集市主题建筑演绎市集幻想 823.45 MB
/简体中文 -

全职业加强但免费,魔域口袋版年中版本送福利 846.55 MB
/简体中文 -
《狙击手冠军》正式推出,享受冠军的射击盛宴 229.62 MB
/简体中文 -
![福彩3D2025年006期[悲殇]太湖钓叟解谜 肚灌满](http://www.www.m.jnyfsp.com/uploads/images/4456950.jpg)
福彩3D2025年006期[悲殇]太湖钓叟解谜 肚灌满 894.76 MB
/简体中文 -
《剑侠世界:起源》“古墓剑影”资料片6.20上线 19.89 MB
/简体中文 -
![2025006期[泪珠]排列三四字真诀](http://www.www.m.jnyfsp.com/uploads/images/6793310.jpg)
2025006期[泪珠]排列三四字真诀 83.74 MB
/简体中文 -

代号氐宿581手游下载 683.35 MB
/简体中文 -
25年006期正老北京本期3D字谜 65.58 MB
/简体中文 -
奇幻生存动作游戏《雾锁王国》Steam夏促史低价78.4元 29.71 MB
/简体中文 -

热浪碰撞《第五人格》第三十四赛季精华1正式上线 61.98 MB
/简体中文 -
西山居姚喆:以精品游戏彰显中国力量,打造全球影响力电竞产品 25.66 MB
/简体中文 -
千禧3D试机号25年006期:238关注数129金码2试机号对应码:[093] 664.17 MB
/简体中文 -
![福彩3D2025年006期[门门通]浅解太湖之一碗汤](http://www.www.m.jnyfsp.com/uploads/images/8772370.jpg)
福彩3D2025年006期[门门通]浅解太湖之一碗汤 268.21 MB
/简体中文 -
《模拟城市:我是市长》繁星夏梦版本全平台推出 35.35 MB
/简体中文 -

湮世哀魇《阴阳师》伊邪那美花合战皮肤即将上线 34.99 MB
/简体中文 -
2024年ChinaJoy拉开帷幕,影核携两款全新力作荣耀登台 961.15 MB
/简体中文 -
双色球25年003期天吉龙头凤尾鸟语断蓝图 688.58 MB
/简体中文 -
25006期一品公子P3天机诗 417.38 MB
/简体中文 -
重振旗鼓,MRCXC歌剧演员华丽蜕变四抓终结比赛 445.37 MB
/简体中文 -

冠军闪耀全服,《剑侠世界:起源》手游“江湖名侠”奖励全览 883.76 MB
/简体中文 -

死神vs火影辉夜新版本下载 18.35 MB
/简体中文 -

手游也能参加奥运,魔域口袋版全新运动会活动 231.69 MB
/简体中文 -

《天下》手游8周年资料片庆今朝7月31日来袭,海量更新量大管饱 12.32 MB
/简体中文 -

《恋与制作人》凌肖生日庆典与他共赴幻境天宫 592.53 MB
/简体中文 -
12小时百万曝光,挑战网易直播记录 29.75 MB
/简体中文 -

万灵诀rpg游戏下载 517.26 MB
/简体中文 -
25年006期3d启机开机号+夏兰{边城金码} 53.96 MB
/简体中文 -

25年006期马后炮解太湖字谜之 751.19 MB
/简体中文 -
双色球23068期牛彩字谜诗迷汇总(天齐整理) 524.21 MB
/简体中文 -
2023年155期3d图迷汇总(三) 819.14 MB
/简体中文 -
全新版本明日更新,魔域口袋版这些福利活动不容错过 176.38 MB
/简体中文 -

23年155期打击者一语定三跨 39.23 MB
/简体中文 -
福彩3D2025年006期[周义宾]解太湖谜语一碗汤 422.87 MB
/简体中文 -

超级大天使英雄官方版下载 93.12 MB
/简体中文 -
《放开那三国3》四周年庆典服开启 499.14 MB
/简体中文 -
哪吒汽车CEO被限制高消费 14.39 MB
/简体中文 -
滑进“蛋”宇宙,蛋仔IP超爽快三消经营手游《蛋仔滑滑》首曝 577.14 MB
/简体中文 -
《蛋仔派对》× Flying DongDong联动治愈而来 928.33 MB
/简体中文 -
《模拟城市:我是市长》繁星夏梦版本登陆苹果AppStore 461.55 MB
/简体中文 -
![[天齐防空警报]23155期3D专家独胆预测:5](http://www.www.m.jnyfsp.com/uploads/images/6100490.jpg)
[天齐防空警报]23155期3D专家独胆预测:5 46.74 MB
/简体中文 -
自由探索乐无边 九阴真经8月资料片漠西特色玩法首曝 234.27 MB
/简体中文 -
《西游:笔绘西行》出场角色九头鸟震撼发布 85.32 MB
/简体中文 -
《西游:笔绘西行》1.1新版本焚扇劫心主题活动前瞻 76.34 MB
/简体中文 -
自由探索乐无边 九阴真经8月资料片漠西特色玩法首曝 526.71 MB
/简体中文 -
重振旗鼓,MRCXC歌剧演员华丽蜕变四抓终结比赛 873.86 MB
/简体中文 -

2023155期桑葚福彩3d和值迷 75.73 MB
/简体中文 -
九游异兽大冒险手游下载 684.15 MB
/简体中文 -
元素大天使官方版下载 19.38 MB
/简体中文 -
财政部:2024年全国财政运行可实现收支平衡 35.92 MB
/简体中文 -
全服运动赢大奖,魔域口袋版8月卡诺萨运动会开幕 632.74 MB
/简体中文 -

第五人格联动女神异闻录5皇家版第一弹上线 958.14 MB
/简体中文 -
marvel super war官方下载 376.53 MB
/简体中文 -
起源之战复仇官方下载 647.63 MB
/简体中文 -

25年006期孟庆会点评+专家一语定胆《保真》 829.72 MB
/简体中文 -

高考顺利,《葫芦娃2》祝考生一飞冲天 12.42 MB
/简体中文 -
《蛋仔滑滑》公测预约福利公布,《蛋仔派对》恐龙蛋套装免费送 483.58 MB
/简体中文 -
以守护之名 ,《战舰世界》联动大力水手开启 28.46 MB
/简体中文 -

灵韵娲福《一梦江湖》新地图巫都玄机等你揭秘 932.67 MB
/简体中文 -
百趣荣耀沙城安卓下载 69.21 MB
/简体中文 -
热血再燃,《远征OL》十五周年新区今日开启狂欢盛典 89.87 MB
/简体中文 -

穿越时空的东方哲学经典——《道德经》 427.99 MB
/简体中文 -
福彩3D2025年006期[智多星]破解太湖谜一碗汤 51.48 MB
/简体中文 -
23155期真黑圣手3D今日字谜 69.88 MB
/简体中文 -
细胞进化论中文版下载 69.38 MB
/简体中文 -
25年006期炫箫工作室所有3d字谜浅释(复制打印版) 456.56 MB
/简体中文 -
p3字汇总 25006期 超级马克p3字谜总汇 891.71 MB
/简体中文 -
25年006期3d试机号后牛魔王七字定码 245.94 MB
/简体中文 -
九游飞跃自我手游下载 11.42 MB
/简体中文 -
九游异兽大冒险手游下载 454.25 MB
/简体中文 -
白熊猫25年003期双色球杀两枚红球图谜 971.98 MB
/简体中文 -

贾宝玉25年003期杀双色球杀蓝号图迷 256.54 MB
/简体中文 -
钢铁机甲斗兽场手机版下载 51.17 MB
/简体中文 -
职业真的平衡了,魔域口袋版全新星辰之力系统上线 491.77 MB
/简体中文 -
《放开那三国2》槃金武将携新时装今日更新 785.83 MB
/简体中文 -
双色球25年003期[常领]五行走势图分析 45.86 MB
/简体中文 -
![福彩3D第2023155期[运财福音]这期参考必出胆码推荐](http://www.www.m.jnyfsp.com/uploads/images/5322060.jpg)
福彩3D第2023155期[运财福音]这期参考必出胆码推荐 47.34 MB
/简体中文 -
双色球25年003期阳光探码+彩民乐图谜 34.81 MB
/简体中文 -

25006期王滨体彩p3字谜 599.95 MB
/简体中文 -
无敌士兵英雄对战下载游戏 18.48 MB
/简体中文 -
![福彩3D2025年006期[唐伯虎]解太湖真诀 仨肉丸](http://www.www.m.jnyfsp.com/uploads/images/208890.jpg)
福彩3D2025年006期[唐伯虎]解太湖真诀 仨肉丸 35.74 MB
/简体中文 -

双色球23068期火箭客一句定蓝迷 75.69 MB
/简体中文 -
【推荐】彩票资讯,更多中奖达人尽在宝彩网! 54.23 MB
/简体中文 -

动作冒险游戏《暗影诅咒:地狱重制版》发售日定于10月31日 72.83 MB
/简体中文 -

《黑光生存进化》不付费删档测试今日开启,海量福利放送 75.12 MB
/简体中文 -
《逆水寒》六周年资料片诡异团本“长生观”定制高质剧情PV 636.73 MB
/简体中文 -
西山居姚喆:以精品游戏彰显中国力量,打造全球影响力电竞产品 623.24 MB
/简体中文 -

《山海剑途》定档7月18日首发,天神女神来助阵 47.38 MB
/简体中文 -
真人互动影像“游戏”,《失业了,我获得了亿万游戏财产!》值得细品 992.19 MB
/简体中文 -
终焉誓约国际服游戏下载 87.72 MB
/简体中文 -
喧嚣再起,《第五人格》2024IVL夏季赛6月8日正式开赛 12.32 MB
/简体中文 -

《暗影格斗3》公测定档8月21日,揭秘国服新内容 615.75 MB
/简体中文 -
《排球少年:新的征程》手游预约开启 飞吧,冲向新的顶端 564.32 MB
/简体中文 -
乐高星球大战破解版下载 579.85 MB
/简体中文 -

崩坏三最新版本steam下载 94.12 MB
/简体中文 -

《暗黑破坏神:不朽》全新活动“精华之路”不容错过 597.57 MB
/简体中文 -
2025年003期双色球专家预测分析汇总(天齐网整理发布) 644.35 MB
/简体中文 -
假面骑士city wars游戏下载 34.56 MB
/简体中文 -
古墓登场,剑指铁浮城《剑侠世界:起源》新资料片震撼公布 743.33 MB
/简体中文 -
《圣斗士星矢:重生2》斗士档案人气圣斗士公布(第一期) 526.84 MB
/简体中文 -
233d155期碎玉跨度字迷 187.42 MB
/简体中文 -
林黛玉25年003期双色球杀蓝号图迷 81.24 MB
/简体中文 -

2025006期蓝仙子一句定三码3d图谜 53.34 MB
/简体中文 -
热浪碰撞《第五人格》第三十四赛季精华1正式上线 25.47 MB
/简体中文 -
23年155期武当玉女掌门一句定三码 16.22 MB
/简体中文 -
火力支援已就位,《战舰世界》拍卖行今日开启 223.38 MB
/简体中文 -

剑灵幻世绘官方版下载 21.72 MB
/简体中文 -
体彩排三23第155期牛彩字谜汇总(天齐网独家整理) 13.66 MB
/简体中文 -
双色球2025年003期名家精选号码推荐总汇 32.28 MB
/简体中文 -
《圣斗士星矢:重生》开启618超值活动,假象者幻塔索斯登场 47.77 MB
/简体中文 -
福彩3D2025年006期[悲殇]太湖钓叟解谜 肚灌满 63.79 MB
/简体中文 -
双色球第25004期哥伦布今天一句杀蓝球 441.89 MB
/简体中文 -
《蛋仔滑滑》公测预约福利公布,《蛋仔派对》恐龙蛋套装免费送 71.11 MB
/简体中文 -
25006期真黑圣手3D今日字谜 861.44 MB
/简体中文 -
《天下》开天计划阶段性工作成果汇报 95.46 MB
/简体中文 -
![25006期[安乐窝]排三胆码字谜](http://www.www.m.jnyfsp.com/uploads/images/248700.jpg)
25006期[安乐窝]排三胆码字谜 961.31 MB
/简体中文 -
少前云图计划taptap客户端下载 948.38 MB
/简体中文 -
《御龙在天手游》国战主播招募,10万金子千元奖金一起拿 24.11 MB
/简体中文 -

《无期迷途》幽零风暴二周年主题活动今日开启 225.26 MB
/简体中文 -
![福彩3D2025年006期[九转]太湖今天释义 顶半天](http://www.www.m.jnyfsp.com/uploads/images/2628730.jpg)
福彩3D2025年006期[九转]太湖今天释义 顶半天 638.46 MB
/简体中文 -

女神联盟手游君主版下载 38.39 MB
/简体中文 -

25006期福彩3d试机号 238(附历史) 396.19 MB
/简体中文 -

25年006期3d试机号后老北京一语定胆 87.48 MB
/简体中文 -

《下一个就是你》:互动影游的求变者 463.23 MB
/简体中文 -

彼岸花开心向往之,《问道》电脑版“幽冥鬼狱”活动进行中 84.57 MB
/简体中文 -
《黑光生存进化》今日开启预约,虚幻5引擎革新游戏体验 77.96 MB
/简体中文 -
争当风云人物,《剑侠世界:起源》“江湖名侠”开启报名 88.63 MB
/简体中文 -
电糖天使降临,《和平精英》携手《百分百出品》跨界联动 45.67 MB
/简体中文 -
高考顺利,《葫芦娃2》祝考生一飞冲天 783.85 MB
/简体中文 -

《暗黑破坏神:不朽》先祖之路时装奥术浩劫明日破界登场 868.41 MB
/简体中文 -
元素契约官方游戏下载 42.71 MB
/简体中文 -
福彩3D155期扶风唤雨歇后语 92.36 MB
/简体中文 -
燕云十六声亮相PS发布会,打入国产3A赛道 693.57 MB
/简体中文 -
漫威全家桶登陆BW, 死侍玩《漫威终极逆转》引爆现场 678.51 MB
/简体中文 -
罗汉图25006期十八罗汉胆码玄机系列图谜 71.77 MB
/简体中文 -

不是哥们,这也太爽了《失业了,我获得了亿万游戏财产!》剧情猜测 882.67 MB
/简体中文 -
25年006期孔方来萃专解太湖钓叟三字诀 471.21 MB
/简体中文 -
好活当赏国产疯狂动物城版战地,老外狂喜 574.13 MB
/简体中文 -
25年006期3d启机开机号+夏兰{边城金码} 953.68 MB
/简体中文 -
火柴蜘蛛侠英雄2城市孤胆车神下载 39.75 MB
/简体中文 -
刀刀爆红包传奇游戏下载 92.62 MB
/简体中文 -
六一更新,《太空杀》免费套装与幸存者双人模式同步上线 382.15 MB
/简体中文 -
长生剑派破世而来,天刀OL全新新服邀你进驻 699.79 MB
/简体中文 -
《方舟生存飞升》新生物恐鳄上线,中心岛地图将开启跨服转移 754.36 MB
/简体中文 -
长生剑派破世而来,天刀OL全新新服邀你进驻 99.29 MB
/简体中文 -

2025年006期福彩3D晚间字谜汇总 958.34 MB
/简体中文 -
23年155期一品公子3d天机诗 74.94 MB
/简体中文 -
全新版本明日更新,魔域口袋版这些福利活动不容错过 23.97 MB
/简体中文 -
灵韵娲福《一梦江湖》新地图巫都玄机等你揭秘 63.36 MB
/简体中文 -
“暖”从何而来?记者走访看羽绒服“科技范” 53.76 MB
/简体中文 -

成吉思汗25年003期双色球杀红球图谜 76.59 MB
/简体中文 -
复古至尊合击手游下载 97.47 MB
/简体中文 -
这游戏真有女玩家,魔域口袋版花魁赛进行中 43.85 MB
/简体中文 -
以拳力赴波涛,《战舰世界》SNK联动正式开启 569.43 MB
/简体中文 -
《英魂之刃口袋版》2024HELM夏季赛线下赛玩家观赛报名开启 34.19 MB
/简体中文 -
罗汉图25006期十八罗汉胆码玄机系列图谜 91.53 MB
/简体中文 -
灵韵娲福《一梦江湖》新地图巫都玄机等你揭秘 28.37 MB
/简体中文 -
真人互动影像“游戏”,《失业了,我获得了亿万游戏财产!》值得细品 33.19 MB
/简体中文 -

长夜将至,2024狼人杀门派联赛第四赛季常规赛圆满结束 482.33 MB
/简体中文 -

福彩3d2023155期一枝独玫胆码图(天齐网原创) 236.16 MB
/简体中文 -
2023155期桑葚福彩3d和值迷 534.94 MB
/简体中文 -
2025年006期3d图迷汇总(六) 117.89 MB
/简体中文 -

崩坏星穹铁道停转的萨尔索图怎么样 崩坏星穹铁道停转的萨尔索图属性详情介绍 198.17 MB
/简体中文 -
因剑侠再相聚,《剑侠世界:起源》手游重现江湖情义 45.18 MB
/简体中文 -
百趣荣耀沙城安卓下载 54.54 MB
/简体中文 -
游戏连结亲情,新华社分享《坦克世界》父亲节短片 482.43 MB
/简体中文 -
互殴群侠传破解版下载 492.17 MB
/简体中文 -
植物球吃僵尸,《球球大作战》联动《植物大战僵尸2》开启 92.18 MB
/简体中文 -

2023年155期东哥无敌解太湖三字诀 23.19 MB
/简体中文 -
全新先祖之路时装失落之潮7月4日强势袭来 755.81 MB
/简体中文 -

重返未来1999旧卷新谈免费衣着活动介绍 421.61 MB
/简体中文 -
《英魂之刃口袋版》精英联赛精彩时刻 赵云白马银枪大招一控四 721.56 MB
/简体中文 -
双色球23068期火箭客一句定蓝迷 31.77 MB
/简体中文 -
《模拟城市:我是市长》即将迎来繁星夏梦版本 54.34 MB
/简体中文 -
体彩p325006期[勇往直前]定胆谜 711.85 MB
/简体中文 -
新门派玄机,《剑侠世界3》资料片“玄机千变”今日上线 423.82 MB
/简体中文 -
天魄拆卸功能上线两种方式任君选择,海量福利等你来 265.53 MB
/简体中文 -
火速集合,营救爷爷《葫芦娃:奇幻世界》如意测试今日开启 727.57 MB
/简体中文 -
故宫北院区核心建筑主体结构封顶 72.39 MB
/简体中文 -

心跳时间到,《蛋仔派对》深度联动《第五人格》重磅再启 949.89 MB
/简体中文 -
送皮肤送英雄,《英魂之刃口袋版》66节清凉泳装登场 69.26 MB
/简体中文 -
12小时百万曝光,挑战网易直播记录 938.22 MB
/简体中文 -
《英魂之刃口袋版》携手《少年歌行》,与你共赴武侠奇缘 954.55 MB
/简体中文 -
首批中央救灾物资已运抵西藏日喀则地震灾区 278.64 MB
/简体中文 -

《月圆之夜》S4赛季舞伴玩法助力对战,新英雄上线战术升华 77.19 MB
/简体中文 -

降魔奇缘,《蛋仔派对》全新外观“僵尸少女不化骨”即将上线 729.95 MB
/简体中文 -
6到飞起,《英魂之刃口袋版》66节狂送皮肤与英雄 78.74 MB
/简体中文 -
25006期福彩3d试机号 238(附历史) 19.94 MB
/简体中文 -
“纸”绘长安繁华,大唐无双手游×洁云联动开启 247.17 MB
/简体中文 -
《方舟生存飞升》新生物恐鳄上线,中心岛地图将开启跨服转移 833.23 MB
/简体中文 -
捉鬼事务所官网在哪下载 最新官方下载安装地址 396.12 MB
/简体中文 -
互殴群侠传破解版下载 673.26 MB
/简体中文 -
双色球25年003期期[黑蝴蝶]本期看好一码围蓝 826.91 MB
/简体中文 -
都是我小弟手机版下载 62.79 MB
/简体中文 -

拳速启航制霸海域,神秘舰长即将进入《战舰世界》 218.39 MB
/简体中文 -

2025年006期天齐网3d试机号后分析 183.93 MB
/简体中文 -
2025年006期3D图谜汇总(九) 534.43 MB
/简体中文 -

少前云图计划bilibili版下载 39.63 MB
/简体中文 -

《剑侠世界:起源》手游“江湖名侠”全服十强出炉 547.61 MB
/简体中文 -
嘉年华流程全面简化,长安穿越指南第一弹来袭 452.81 MB
/简体中文 -
《远征OL》联动《饿了么》今日开启美食节新区饕餮 25.13 MB
/简体中文 -
《圣斗士星矢:重生2》手游CG《重塑》发布,公测倒计时7天 823.97 MB
/简体中文 -

新芽托起荒芜,《时空中的绘旅人》全新异色画卷8月10日上线 153.89 MB
/简体中文 -
《下一个就是你》:互动影游的求变者 549.71 MB
/简体中文 -
《狙击手冠军》正式推出,享受冠军的射击盛宴 14.39 MB
/简体中文 -
灵韵娲福《一梦江湖》新地图巫都玄机等你揭秘 45.94 MB
/简体中文 -
九游神火大陆手游下载 72.92 MB
/简体中文 -
《英魂之刃口袋版》66节狂欢庆典:英雄及皮肤大放送 775.74 MB
/简体中文 -
夏日颜值盛典全民征集开启,永久时装0元带走 33.62 MB
/简体中文 -

《恋与制作人》白起生日庆典 以爱为翼天高风远 292.53 MB
/简体中文 -

《西游:笔绘西行》1.1新版本焚扇劫心公布 97.65 MB
/简体中文 -
九游修仙绘卷手游下载 29.34 MB
/简体中文 -

网易游戏ChinaJoy参展盛况回顾:玩家热情见证热爱力量 366.18 MB
/简体中文 -
九游飞跃自我手游下载 833.17 MB
/简体中文 -
无敌士兵英雄对战下载游戏 84.66 MB
/简体中文 -

父子同心,《保卫要塞》祝所有父亲节日快乐 874.68 MB
/简体中文 -
【方块方舟】欢乐像素世界,童趣无限,儿童节版本开启 91.11 MB
/简体中文 -
荒野迷城官宣游戏代言人,东方拳王张志磊降临荒野 43.72 MB
/简体中文 -
全新版本明日更新,魔域口袋版这些福利活动不容错过 29.48 MB
/简体中文 -
刚刚,黄圣依、杨子、麦琳、李行亮等发文 57.95 MB
/简体中文 -
最后的原始人九游版下载 36.45 MB
/简体中文 -
少年封印师桔梗手游下载 181.37 MB
/简体中文 -
双色球23068期蝴蝶结一句杀蓝字谜 82.15 MB
/简体中文 -

镇魂街武神躯下载游戏 638.66 MB
/简体中文 -
九阳神功起源手游下载 546.64 MB
/简体中文 -

神仙姐姐降临江湖,《剑侠世界:起源》古墓派达人团亮相 84.79 MB
/简体中文 -
代言人大鹏:来大话交个新“鹏”友,去专属新服玩个痛快 76.61 MB
/简体中文 -
口袋玩家生存之战游戏下载 71.38 MB
/简体中文 -

一分钟上手,《漫威终极逆转》无限测试今日开启 41.86 MB
/简体中文 -
《侠客风云传OL》周年庆盛典来袭,海量福利邀您共赴江湖风云 568.96 MB
/简体中文 -
夏日新品,《剑侠世界3》新坐骑新宠物霸气登场 54.17 MB
/简体中文 -
2023年155期千万大奖一语定三胆 871.56 MB
/简体中文 -

7月16日《保卫要塞》S1新赛季开启,玩法新调整 57.39 MB
/简体中文 -
25年006期本期体彩P3正版藏机诗汇总 778.42 MB
/简体中文 -
全新激萌灵兽外观免费获得,这个夏日简直好玩又好看 83.33 MB
/简体中文 -
年中重大版本盛大公测,魔域口袋版三大系统全新上线 41.73 MB
/简体中文 -
《排球少年:新的征程》手游预约开启 飞吧,冲向新的顶端 35.68 MB
/简体中文 -

藏机图2025003期天齐原创双色球藏机图迷 968.14 MB
/简体中文 -
钢铁机甲斗兽场手机版下载 583.58 MB
/简体中文 -
25年006期3d试机号后晚秋一语看奖号 25.16 MB
/简体中文 -
龙珠超英雄手机版下载 93.47 MB
/简体中文 -
现在还有夺金点,魔域口袋版火热夺魁中 83.27 MB
/简体中文 -
新门派玄机,《剑侠世界3》全新资料片6.12上线 772.71 MB
/简体中文 -
八载同行,《FGO》简中版八周年庆典狂欢今日正式启动 98.34 MB
/简体中文 -
真正做到“硬”控,这个职业原来可以如此搭配 211.55 MB
/简体中文 -

如何提升最有性价比,魔域口袋版最新版本提升攻略 577.42 MB
/简体中文 -
植物球吃僵尸,《球球大作战》联动《植物大战僵尸2》开启 895.51 MB
/简体中文 -
2024年ChinaJoy拉开帷幕,影核携两款全新力作荣耀登台 76.35 MB
/简体中文 -
2023年155期3D图谜汇总(二) 458.99 MB
/简体中文 -

果盘运动斗士手游下载 94.88 MB
/简体中文 -
一分钟上手,《漫威终极逆转》无限测试今日开启 48.89 MB
/简体中文 -
极限博弈,FPX.ZQ求生者无瑕配合逆境三出 493.59 MB
/简体中文 -
秦时明月和铠甲勇士拍电影,国产第一IP宇宙击破多厨次元壁 28.65 MB
/简体中文 -
25006期[安乐窝]排三胆码字谜 62.96 MB
/简体中文 -
2025年006期3D图谜汇总(九) 72.64 MB
/简体中文 -

25006期3d新北京+粼粼字谜+东北人+西部佳音 944.72 MB
/简体中文 -

提升这这这么大,魔域口袋版全新匠石伤害评测 56.54 MB
/简体中文 -
2025006期[泪珠]排列三四字真诀 32.96 MB
/简体中文 -

奥特曼无限对决手机版下载 777.38 MB
/简体中文 -
KK官方对战平台存档翻倍活动劲爆开启 47.69 MB
/简体中文 -
漫威超级争霸战虫虫助手版下载 26.85 MB
/简体中文 -

混帐家伙和拳头手机版下载 212.32 MB
/简体中文 -

天天有喜25年003期杀双色球红球图迷 18.52 MB
/简体中文 -
热浪碰撞《第五人格》第三十四赛季精华1正式上线 39.38 MB
/简体中文 -
福彩3D2025年006期[十万火]精解太湖钓叟 仨肉丸 612.85 MB
/简体中文 -
25006期福彩3D麦久免费综合预测汇总(天齐网独家整理) 896.77 MB
/简体中文 -

KK官方对战平台怀旧专区正式上线,回到RPG黄金年代 12.94 MB
/简体中文 -
2024年全年全国居民消费价格比上年上涨0.2% 456.62 MB
/简体中文 -

崩坏星穹铁道记忆开拓者技能是什么 397.63 MB
/简体中文 -
角逐最强帮会,《剑侠世界:起源》大型帮战点燃热血 96.44 MB
/简体中文
最新合集
- 美高梅棋牌官网入口
- kaiyun全站登录网页入口
- 金沙棋牌js6666手机版
- 问鼎娱乐
- ng28.666官网版
- 开元棋盘财神捕鱼官网版下载2023
- lol押注正规平台官网
- 南宫28ng娱乐平台游戏特色
- 开yun体育官网入口登录体育
- 771771威尼斯.cmapp
- 澳门威尼克斯人网站
- 开yun体育官网入口登录app
- pg电子娱乐平台
- 爱游戏app官方网站登录入口
- 开yun体育官网入口登录app
- pg娱乐电子游戏
- 开元棋app官方下载
- 南宫ng注册平台入口
- im电竞
- 爱游戏app最新官网登录
- im电竞
- 开元棋盘app官方版下载_开元棋盘app官网版下载-跑跑车
- 星空体育平台官网入口
- 771771威尼斯.cmapp
 澳门威尼克斯人网站
澳门威尼克斯人网站 澳门威尼克斯人网站
澳门威尼克斯人网站 星空综合体育app下载
星空综合体育app下载 kaiyun全站登录网页入口
kaiyun全站登录网页入口 pg赏金大对决试玩版
pg赏金大对决试玩版 kaiyun全站登录网页入口
kaiyun全站登录网页入口 c7官网app下载安装
c7官网app下载安装 澳门新葡萄新京5303游戏特色
澳门新葡萄新京5303游戏特色 开元棋盘财神捕鱼官网版下载2023
开元棋盘财神捕鱼官网版下载2023 九游会·j9官方网站
九游会·j9官方网站 pg电子赏金试玩app
pg电子赏金试玩app 金沙棋牌js6666手机版
金沙棋牌js6666手机版 kaiyun全站登录网页入口
kaiyun全站登录网页入口 pg网赌软件下载
pg网赌软件下载 澳门威尼克斯人网站
澳门威尼克斯人网站 十大体育外围平台app
十大体育外围平台app 免费pg电子游戏麻将
免费pg电子游戏麻将 pg麻将胡了试玩平台
pg麻将胡了试玩平台 ng28.666官网版
ng28.666官网版 kai云体育app官网版下载
kai云体育app官网版下载 im电竞
im电竞 kaiyun官方网站登录入口
kaiyun官方网站登录入口 kaiyun全站app登录入口
kaiyun全站app登录入口 鼎盛注册平台
鼎盛注册平台 威尼斯wns.8885556
威尼斯wns.8885556 金沙棋牌js6666手机版
金沙棋牌js6666手机版 九游娱乐
九游娱乐 开元棋官方正版下载
开元棋官方正版下载 开元棋app官方下载
开元棋app官方下载 pg赏金女王单机版试玩平台
pg赏金女王单机版试玩平台 云开·全站app登录网页入口
云开·全站app登录网页入口 南宫ng注册平台入口
南宫ng注册平台入口 365wm完美体育手机平台
365wm完美体育手机平台